Apr 17, 2026
Building a Video AI Pipeline: From Ingestion to Actionable Insight
A technical guide for engineers on building a scalable video AI pipeline. Learn to transform raw video into actionable insights using modern computer vision and ML.
Beyond the Pixels: The Data Trapped in Your Video Streams
According to Cisco, video data now constitutes over 80% of all internet traffic, a staggering figure that underscores a fundamental shift in how we generate and consume information. For enterprises, this explosion of video from security cameras, body cams, user-generated content, and industrial sensors represents a colossal, largely untapped asset. The challenge, however, is that this data is inherently unstructured and opaque. A raw video file is a sequence of pixels, not a database of searchable events. Without the right tools, finding a specific two-minute clip of a forklift safety violation in a month's worth of warehouse footage is an impossible, needle-in-a-haystack problem.
This is where a video AI pipeline becomes not just a competitive advantage, but a core operational necessity. It is a sophisticated, multi-stage system designed to systematically ingest, process, analyze, and index video content at scale, transforming it from a passive storage burden into an active, queryable data source. This process moves beyond simple object detection, enabling deep semantic understanding of actions, interactions, and environmental context. By building an effective pipeline, organizations can unlock critical insights that drive efficiency, enhance security, and create entirely new user experiences, turning passive surveillance into proactive intelligence.
The imperative to build these pipelines is growing. The video analytics market is projected to reach $14.9 billion by 2026, driven by the urgent need to make sense of this data deluge. For data scientists and machine learning engineers, the task is to architect systems that are not only accurate but also efficient, scalable, and capable of delivering insights with minimal latency. The goal is to create a seamless flow from raw video ingestion to the final, actionable insight on a dashboard or an automated alert sent to a device, all while managing immense computational complexity and data volume.

The Four Bottlenecks of Unstructured Video Data
Attempting to manage and analyze video content without a purpose-built AI pipeline introduces significant operational friction and strategic blind spots. These challenges are not minor inconveniences; they are fundamental bottlenecks that prevent organizations from realizing the full value of their visual data. Each bottleneck imposes a tangible cost in terms of time, resources, and missed opportunities, making a compelling case for a more intelligent, automated approach to video analysis. The problems compound at scale, turning manageable issues with a few dozen video files into intractable crises with petabytes of streaming data.
First, scalability and ingestion overload present an immediate infrastructure crisis. With video making up the vast majority of enterprise data, traditional file systems and databases are simply not equipped to handle the throughput and storage demands. Ingesting thousands of concurrent high-resolution streams can saturate networks and overwhelm storage arrays, leading to dropped frames and data loss. The cost of simply storing this ever-growing archive becomes prohibitive, especially when the data within it remains inaccessible and therefore provides no return on investment. This forces engineering teams into a reactive cycle of constantly provisioning more hardware rather than building value.
Second, the manual review tax is a massive drain on human capital. Relying on human operators to watch video footage for specific events is incredibly inefficient, expensive, and prone to error. Research from NVIDIA highlights that AI-powered analytics can reduce this manual review time by up to 90%. For a security team reviewing incident reports or a content moderation team screening user uploads, this translates to thousands of person-hours saved. More importantly, it frees up skilled personnel to focus on higher-level analysis and decision-making rather than the monotonous task of watching screens, which also suffers from fatigue and attention-span limitations.
Third, the inability to perform deep, semantic search renders large video archives practically useless. Traditional systems rely on manually entered metadata and file names for discovery. This approach fails when you need to find complex events that defy simple keywords, such as "a customer looking confused near the electronics aisle" or "a near-miss incident between two vehicles at an intersection." IBM notes that approximately 80% of enterprise data is unstructured, and video is a primary component. Without the ability to query the actual content of the video, this vast repository of information remains dark, and the specific, high-value moments within it are lost forever.
Finally, high latency in insight generation cripples any hope for real-time responsiveness. In many critical applications, such as industrial safety or live event security, the value of an insight diminishes rapidly with time. An alert about a safety hazard that arrives 30 minutes after the event is a report, not a prevention tool. Traditional batch-processing approaches to video analysis introduce significant delays between data capture and insight delivery. This latency gap means that by the time you understand what happened, the opportunity to intervene or mitigate has already passed, undermining the entire purpose of the monitoring system.
The Core Components of a Modern Video Pipeline
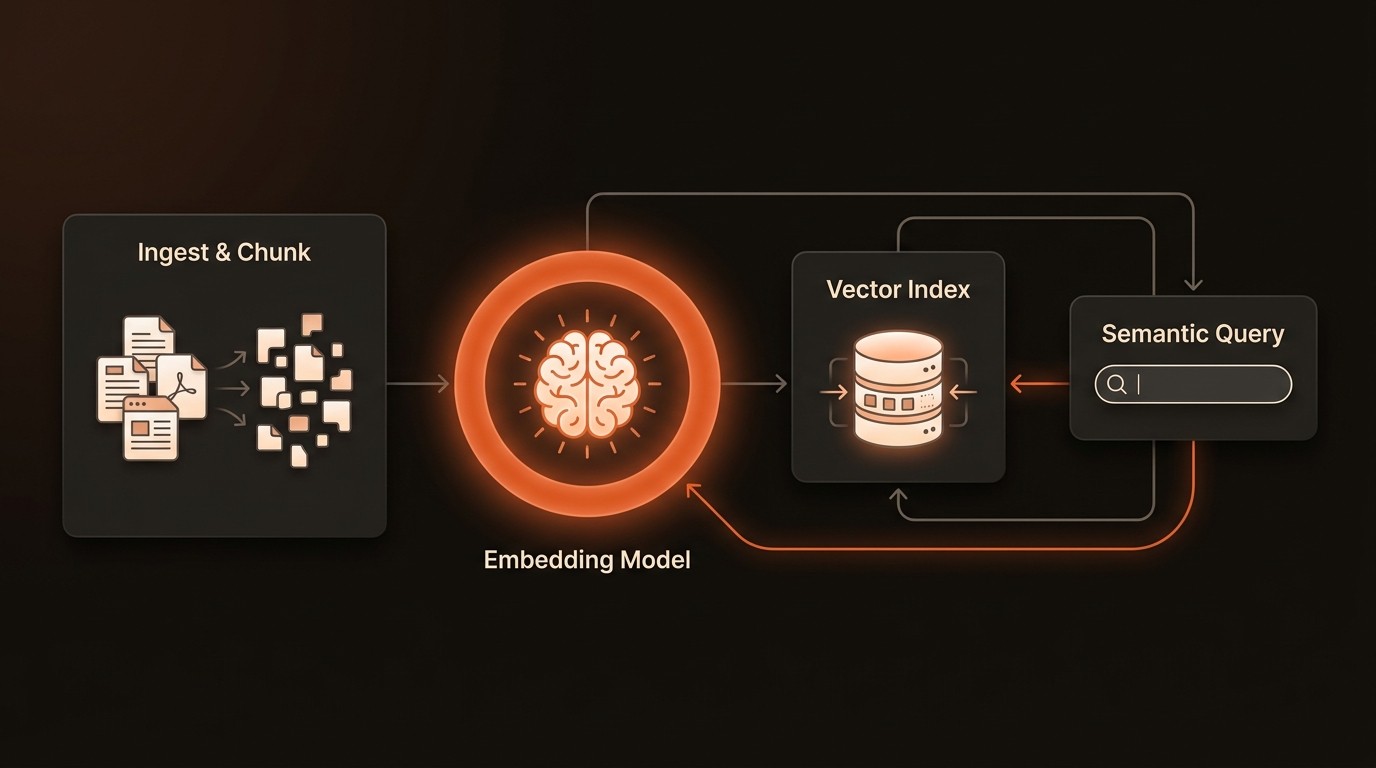
A modern video AI pipeline is an assembly line for intelligence, breaking down the complex task of understanding video into a series of manageable, automated stages. Each component plays a critical role in refining raw data, extracting meaningful features, and making the content accessible for analysis. This architectural approach is designed for scalability and modularity, allowing engineers to swap in different models or processing techniques as technology evolves. Understanding these core components is the first step toward designing a system that can handle the demands of real-world video data.
Data Ingestion and Pre-processing
This initial stage is the foundation of the entire pipeline. It involves capturing video from various sources-IP cameras, file uploads, live streams-and preparing it for analysis. The first step is decoding, where compressed video (e.g., H.264, HEVC) is converted into a sequence of raw image frames. This is followed by pre-processing, which includes tasks like resizing frames to a standard dimension, normalizing pixel values, and potentially adjusting color or brightness to ensure consistency for the downstream AI models. This stage must be highly efficient and robust, capable of handling diverse formats, resolutions, and frame rates without becoming a bottleneck. For instance, a system might use a library like FFmpeg to extract frames at a specified rate, such as one frame per second, to balance computational load with temporal detail.
Feature Extraction with Computer Vision Models
Once the video is broken down into clean, consistent frames, the core analysis begins. This is where computer vision models are applied to extract meaningful features. This goes far beyond simple object detection. Modern pipelines use a varietyis of models to create a rich, multi-layered understanding of the content. A Convolutional Neural Network (CNN) might identify objects, while a separate model analyzes poses to understand human actions, and another processes audio tracks to detect specific sounds. The most critical output of this stage is often a set of vector embeddings-dense numerical representations that capture the semantic essence of the frame's content. These vectors allow for nuanced similarity comparisons that are impossible with simple text tags.
Indexing and Vector Search
With features and embeddings extracted, the next challenge is to make them searchable at scale. Storing terabytes of vector data and querying it with low latency is a specialized task that traditional databases are not built for. This is where a vector database or a specialized multimedia database like VideoDB becomes essential. These systems are optimized for high-dimensional data and can perform incredibly fast similarity searches. Instead of asking for a video with the tag "car," you can provide an image of a specific car and ask the system to find all video segments containing similar vehicles. This enables powerful, content-based retrieval. The indexing process organizes these vectors in a way that makes searching for the nearest neighbors (the most similar content) computationally feasible, even across billions of data points.
Insight Generation and Action Layer
The final stage of the pipeline is where the indexed data is used to generate value. This "action layer" translates the results of a query or a real-time detection into a usable output. This could be a dashboard visualizing customer traffic patterns in a retail store, an instant SMS alert sent to a plant manager when a piece of machinery malfunctions, or an API endpoint that allows an application to retrieve and display relevant video clips. This layer is responsible for business logic, data visualization, and integration with other enterprise systems. It's the crucial link that closes the loop between raw data and a concrete, data-driven decision or automated action.
Video AI by the Numbers
Here's what the data reveals about the challenges and opportunities in the video analytics landscape:
Metric | Data Point | Implication for Your Pipeline |
|---|---|---|
Market Growth | Projected to reach $14.9 billion by 2026 | Indicates strong, sustained investment and innovation in video AI technologies and platforms. |
Manual Review Inefficiency | AI can reduce manual review time by up to 90% | Automation is the key to unlocking productivity and scaling operations without linear cost increases. |
Unstructured Data Challenge | ~80% of enterprise data is unstructured, with video as a key part | A robust pipeline is essential for turning this massive, dark data source into a queryable asset. |
Internet Traffic Dominance | Video comprises over 80% of all internet traffic | Your pipeline's architecture must be designed for massive scale and high-throughput ingestion. |
Cloud Infrastructure Savings | Cloud-based pipelines can cut costs by up to 50% vs. on-prem | Leveraging cloud services offers a more scalable, flexible, and cost-effective deployment model. |
Architecting an Efficient and Scalable Pipeline
Building a high-performance video AI pipeline requires more than just stitching together open-source libraries. It demands a thoughtful architectural approach focused on solving the core bottlenecks of scale, speed, and searchability. The goal is to create a system that not only works on a small dataset but can gracefully scale to handle thousands of concurrent streams and petabytes of archived footage. This involves leveraging automation, adopting modern search paradigms, and designing for a cloud-native environment to maximize efficiency and minimize operational overhead.
Automated Metadata and Embedding Generation
The first step in breaking free from manual inefficiency is to fully automate the process of understanding video content. A well-architected pipeline should automatically trigger a series of AI models upon video ingestion. These models work in concert to generate a rich tapestry of time-stamped metadata: object detections, face recognition, action classifications, audio event detection, and optical character recognition (OCR). Crucially, it also generates the vector embeddings that power semantic search. This automated enrichment, often managed by a platform like VideoDB, transforms each video into a structured data object, directly addressing the 90% reduction in manual labor cited by NVIDIA. The output is a rich, machine-readable index that serves as the foundation for all subsequent analysis.
Multi-Modal Search Capabilities
To solve the semantic search problem, the pipeline must move beyond simple keywords and embrace multi-modal queries. This means enabling users to search using different types of input to find what they're looking for. A truly effective system allows you to search by text ("a person in a yellow vest climbing a ladder"), by image (uploading a photo to find all video clips containing that person or object), by audio ("find all clips with the sound of breaking glass"), or even by a combination of these. This is made possible by the indexed vector embeddings. The system converts the query-whether it's text or an image-into its own vector and then performs a similarity search to find the closest matches in the video database, delivering highly relevant results that would be impossible to find with manual tagging.
Real-Time Event Detection and Alerting
Addressing the latency bottleneck requires shifting from a batch-processing mindset to a real-time, stream-processing architecture. For applications in safety and security, the pipeline must analyze video frames as they arrive, not hours later. This is achieved by deploying AI models at the edge (on or near the camera) or on a low-latency cloud infrastructure. The system is configured with specific rules or triggers, such as detecting a person entering a restricted area or a vehicle moving in the wrong direction. When a trigger condition is met, the pipeline generates an immediate alert via SMS, email, or an API call. This capability transforms a passive monitoring system into a proactive one, enabling immediate intervention and preventing incidents before they escalate.
Scalable Cloud-Native Architecture
Finally, to handle the sheer volume of video data, a cloud-native design is paramount. This approach leverages cloud services like object storage (e.g., Amazon S3), serverless functions (e.g., AWS Lambda for pre-processing), and managed container orchestration (e.g., Kubernetes) to build a flexible and resilient pipeline. This architecture can automatically scale compute resources up or down based on demand, ensuring you only pay for what you use. As highlighted by Amazon Web Services, this can reduce infrastructure costs by up to 50% compared to maintaining a large on-premise hardware cluster. Using a managed video AI platform like VideoDB further abstracts away this complexity, providing a scalable backend without requiring a dedicated DevOps team to manage it.
The Pipeline in Practice: From Theory to Impact
An effective video AI pipeline delivers tangible business value across a wide range of industries. By moving from theoretical architecture to practical application, organizations can solve specific, high-impact problems. The true measure of a pipeline's success is its ability to translate raw video into measurable improvements in efficiency, safety, and customer experience. These real-world examples illustrate how the components of the pipeline come together to create powerful, data-driven solutions.
Smart Retail: Optimizing Store Layout and Customer Flow
In the competitive retail sector, understanding customer behavior is critical. A leading retail chain deployed a video AI pipeline using their existing in-store security cameras. The system was configured to anonymously track shopper movement, creating heatmaps of store traffic, measuring dwell time at promotional displays, and analyzing queue lengths at checkout counters. This wasn't about identifying individuals, but about understanding aggregate patterns. By analyzing this data, store managers could A/B test different product placements and layouts. The result was a 15% increase in sales for high-margin products placed in newly identified high-traffic zones and a 40% reduction in average checkout wait times after optimizing staff allocation based on real-time queue data.
Industrial Safety: Proactive Hazard Detection
A large logistics company faced challenges with maintaining safety compliance in its busy warehouses. They implemented a real-time video AI pipeline to monitor feeds from cameras overlooking loading docks and forklift traffic areas. The system was trained to detect specific safety violations, such as workers not wearing personal protective equipment (PPE) or forklifts moving at unsafe speeds. When a violation was detected, an instant alert with a short video clip was sent to the on-duty floor manager's tablet. This proactive system allowed for immediate intervention and correction. Within six months of deployment, the company reported a 60% reduction in safety incidents and a corresponding decrease in workplace injury claims.
Media & Entertainment: Automating Content Discovery
A major media company with a vast archive of historical news footage struggled to make its content accessible to producers. Manually logging and tagging decades of video was an impossible task. They deployed a video AI pipeline to process the entire archive. The system used speech-to-text to create transcripts, facial recognition to identify public figures, and OCR to read on-screen text like chyrons and headlines. This created a deeply searchable database. Now, a producer looking for footage of a specific politician discussing a certain topic in the 1990s can find relevant clips in seconds instead of days. This accelerated content creation workflows and unlocked the monetary value of their archival assets.
Industry Voices on the Future of Video AI
Jensen Huang, CEO of NVIDIA, emphasized in a GTC keynote that accelerated computing and AI are the essential ingredients for processing the planet's vast and growing streams of video data, enabling the real-time insights and automation that define the next wave of computing. (2023)
Fei-Fei Li, Professor of Computer Science at Stanford University, highlighted in a lecture the critical importance of developing robust and ethical AI algorithms for video analysis. She stressed the need to build systems that ensure fairness and actively work to prevent the amplification of societal biases, which is a crucial consideration as these technologies become more widespread. (2020)
Your Five-Step Roadmap to Implementation
Embarking on building a video AI pipeline can seem daunting, but a structured, phased approach can de-risk the project and ensure alignment with business objectives. Instead of attempting a massive, all-encompassing build, focus on delivering value incrementally. This roadmap outlines five key steps to guide you from initial concept to a scalable, operational pipeline that delivers measurable results.
Define a High-Value, Bounded Use Case
Before writing a single line of code, identify a specific business problem that video analysis can solve. Don't start with a vague goal like "improve operations." Instead, target a concrete issue, such as "reduce false-positive security alerts at the main entrance by 50%" or "automate the quality control process for product line X." A well-defined scope makes it easier to measure success and secure stakeholder buy-in for future expansion.
Audit Your Data and Infrastructure
Assess the current state of your video data. What are the sources? What is the quality, format, and resolution of the video feeds? Where is the data currently stored? Evaluate your existing compute and network infrastructure to understand if it can support the demands of a PoC. This audit will inform key architectural decisions, such as whether to process data at the edge or in the cloud, and what pre-processing steps will be necessary.
Select the Right Toolchain (Build vs. Buy)
Evaluate the trade-offs between building the pipeline from scratch using open-source libraries (like OpenCV, PyTorch, and TensorFlow) and leveraging a managed platform. A build-it-yourself approach offers maximum flexibility but requires significant expertise and development time. A managed solution, such as a specialized video database like VideoDB, can dramatically accelerate development by providing a pre-built, scalable backend for ingestion, indexing, and search, allowing your team to focus on the application logic.
Develop a Proof of Concept (PoC)
With a clear use case and toolchain, build a small-scale version of your pipeline. The goal of the PoC is to prove technical feasibility and demonstrate business value. Process a limited dataset-perhaps a week's worth of footage from a single location-and measure its performance against your predefined metrics. This is the stage to iron out technical kinks and gather feedback from end-users to refine the solution.
Iterate, Scale, and Monitor
Once the PoC is successful, create a plan to scale the solution. This involves deploying the pipeline to more locations or data sources and hardening it for production use. It is critical to implement MLOps practices for ongoing monitoring. AI models can drift over time as real-world conditions change, so you need processes to monitor accuracy, retrain models with new data, and manage the model lifecycle to ensure the pipeline remains effective and unbiased.
Common Questions About Video AI Pipelines
Q: What is the difference between video analytics and a video AI pipeline?
A: Video analytics is the broad term for using software to analyze video, which can include simple rule-based systems (e.g., motion detection). A video AI pipeline is a specific, end-to-end architecture that uses machine learning and computer vision models to perform complex, content-aware analysis, including ingestion, feature extraction, indexing, and search, to deliver deep, semantic insights at scale.
Q: How much data is needed to train a custom model for a video pipeline?
A: This depends heavily on the task's complexity. For common tasks like detecting people or cars, you can often use pre-trained models with little to no new data. For highly specialized tasks, like identifying a unique type of manufacturing defect, you may need to collect and label thousands of examples. The best practice is to start with a pre-trained model and fine-tune it on a smaller, specific dataset.
Q: Can this pipeline run on-premise, in the cloud, or in a hybrid model?
A: Yes, all three deployment models are possible. A fully cloud-based pipeline offers the most scalability and can reduce upfront infrastructure costs by up to 50%. An on-premise deployment might be necessary for environments with limited internet connectivity or strict data residency requirements. A hybrid model is also common, where initial processing or inference happens on edge devices (on-prem) and the resulting metadata is sent to the cloud for centralized storage and analysis.
Q: How does a system like VideoDB handle privacy and data security?
A: Privacy is a critical design consideration. Leading platforms like VideoDB incorporate features to help with compliance, such as the ability to run blurring or anonymization models as part of the ingestion process. Security is handled through robust access controls, data encryption at rest and in transit, and secure APIs. It is essential to architect the pipeline in a way that adheres to regulations like GDPR and CCPA from the outset.
Q: What are the biggest challenges in maintaining a video AI pipeline over time?
A: The two biggest long-term challenges are model drift and data quality. Model drift occurs when the real-world data changes over time, causing the AI model's accuracy to degrade. This requires a robust MLOps strategy for continuous monitoring and retraining. Data quality issues, such as changes in camera angles, lighting conditions, or video compression, can also impact performance, necessitating ongoing monitoring and adaptation of the pipeline's pre-processing stages.
Key Takeaways
Video is the largest and fastest-growing data source, with over 80% of internet traffic, but most of it is unstructured and inaccessible.
A video AI pipeline automates the transformation of raw video into searchable, actionable data, reducing manual review by up to 90%.
Modern pipelines rely on vector embeddings and specialized databases like VideoDB to enable powerful semantic and multi-modal search.
A cloud-native architecture is crucial for scalability and can reduce infrastructure costs by up to 50% compared to on-premise solutions.
Successful implementation starts with a well-defined use case and follows an iterative path from a small proof of concept to a fully scaled, monitored system.









