Apr 17, 2026
Optimizing RAG with Advanced Chunking Strategies
Explore chunking techniques in Retrieval-Augmented Generation to enhance information retrieval and improve content quality.
Enhancing RAG with Strategic Chunking
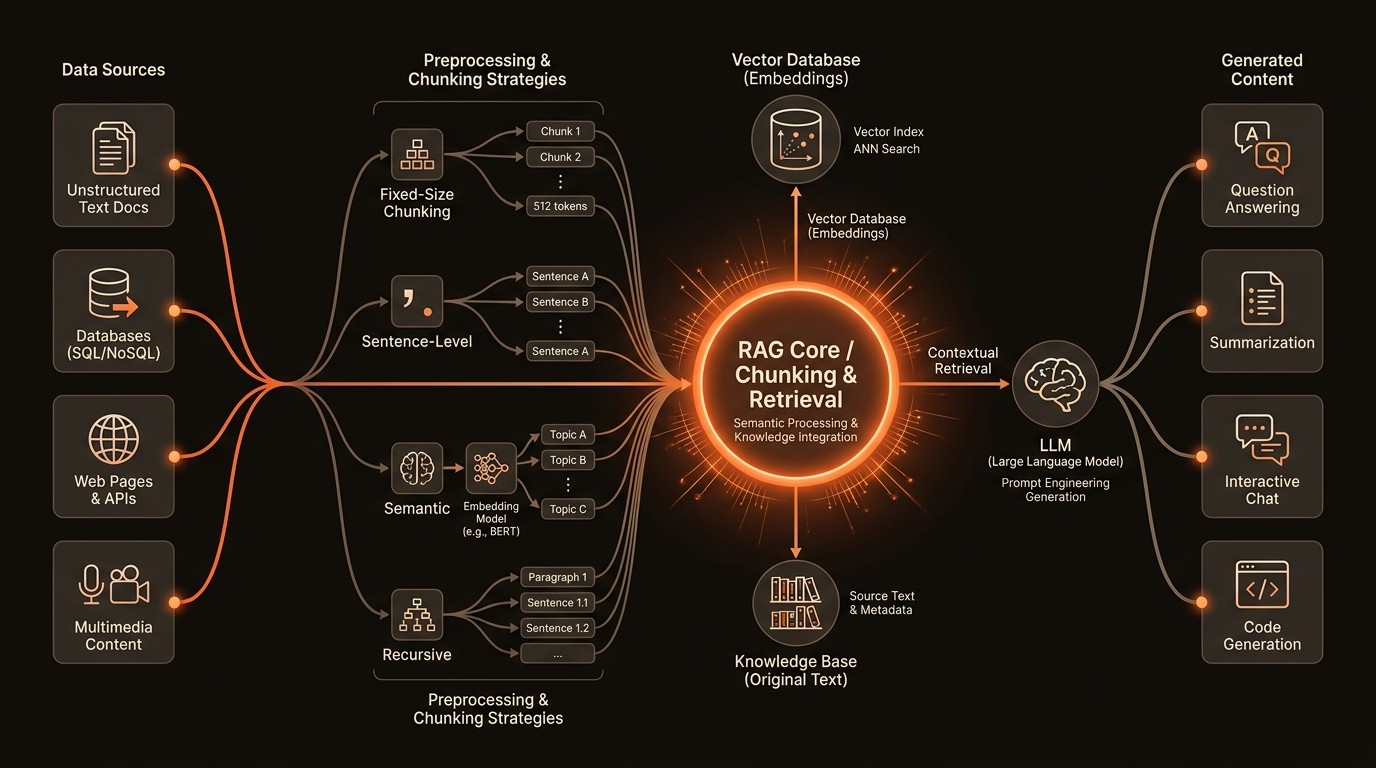
In the realm of Retrieval-Augmented Generation (RAG), the ability to effectively retrieve and utilize external knowledge is paramount. According to a 2023 report by Google AI, RAG systems can significantly improve the accuracy of language model outputs by grounding them in external knowledge. However, the challenge lies in optimizing the retrieval process to ensure that the information fed into the language model is both relevant and coherent. This is where chunking strategies come into play, offering a method to enhance the retrieval process by breaking down information into manageable pieces.
Chunking is not just about splitting text into smaller parts; it's about strategically segmenting information to maximize retrieval efficiency and content generation quality. Effective chunking can significantly impact the relevance and coherence of retrieved information in RAG pipelines, as highlighted in a 2023 study published on arXiv. By employing various chunking techniques, developers and AI practitioners can optimize their RAG systems to deliver more accurate and contextually aware responses.
The importance of chunking is further underscored by its ability to reduce hallucination in large language models. As noted by IBM Research in 2024, RAG systems can mitigate hallucination by providing verifiable source material, ensuring that the generated content is grounded in reality. This blog will explore different chunking strategies, including fixed-size, content-aware, and semantic chunking, providing practical examples and considerations for enhancing RAG pipelines.
Defining the Chunking Challenge
One of the primary challenges in RAG systems is determining the optimal chunk size for information retrieval. Fixed-size chunking, while straightforward, often fails to account for the natural structure of the text, leading to fragmented information that can disrupt the coherence of the generated content. For instance, splitting a paragraph mid-sentence can result in incomplete thoughts being retrieved, which can confuse the language model and degrade the quality of the output.
Content-aware chunking attempts to address this issue by considering the natural breaks in the text, such as sentences or paragraphs. However, this approach can be computationally expensive, as it requires additional processing to identify these breaks. Moreover, content-aware chunking may still struggle with complex documents where the logical structure does not align neatly with sentence or paragraph boundaries.
Semantic chunking offers a more sophisticated solution by grouping text segments based on meaning rather than arbitrary size or structure. According to Hugging Face in 2023, semantic chunking can improve the retrieval of contextually relevant information, enhancing the overall quality of the generated content. However, implementing semantic chunking requires advanced natural language processing techniques to accurately assess the semantic relationships between text segments.
Another significant challenge is balancing the amount of information provided to the language model with the computational cost. As Ronan Le Bras from Pinecone noted in 2023, optimizing chunking strategies is crucial for providing the right amount of context to the language model without overwhelming it or incurring excessive computational costs. This balance is essential for maintaining the efficiency and effectiveness of RAG systems.
Understanding Chunking in RAG
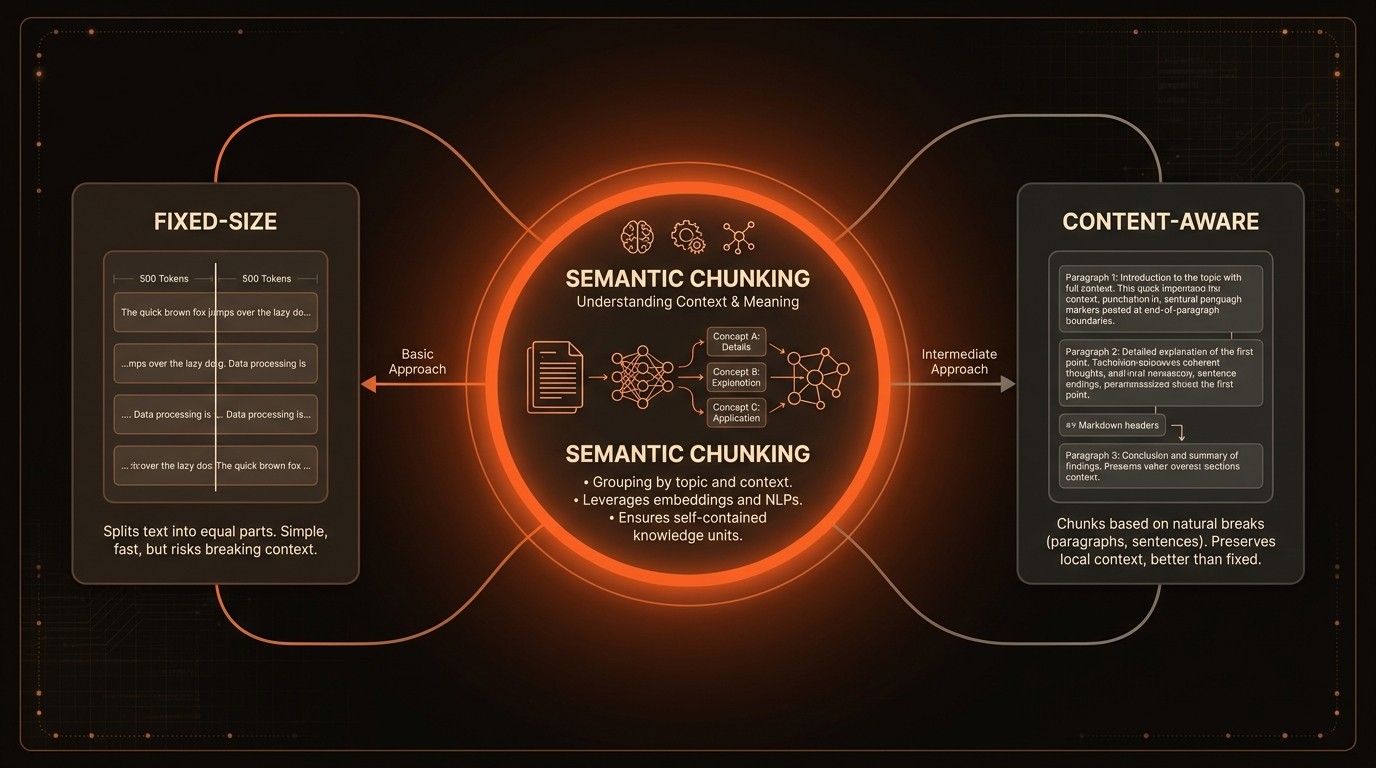
Fixed-Size Chunking
Fixed-size chunking involves dividing text into equal-sized segments, regardless of the content. This method is simple to implement and computationally efficient, making it a popular choice for initial RAG implementations. However, it often leads to fragmented information, as it does not consider the natural structure of the text. This can result in incomplete or incoherent retrievals, impacting the quality of the generated content.
Content-Aware Chunking
Content-aware chunking improves upon fixed-size chunking by considering the natural breaks in the text, such as sentences or paragraphs. This approach aims to preserve the logical structure of the information, enhancing the coherence of the retrieved content. However, it requires additional processing to identify these breaks, which can increase computational costs. Despite this, content-aware chunking is often more effective than fixed-size chunking in maintaining the integrity of the information.
Semantic Chunking
Semantic chunking takes a more advanced approach by grouping text segments based on their meaning. This method leverages natural language processing techniques to assess the semantic relationships between text segments, ensuring that the retrieved information is contextually relevant. According to Hugging Face in 2023, semantic chunking can significantly enhance the quality of the generated content by providing more accurate and meaningful context to the language model.
Balancing Information and Cost
A critical aspect of chunking in RAG systems is balancing the amount of information provided to the language model with the computational cost. As Ronan Le Bras from Pinecone highlighted in 2023, optimizing chunking strategies is essential for providing the right amount of context without overwhelming the language model or incurring excessive computational costs. This balance is crucial for maintaining the efficiency and effectiveness of RAG systems.
By the Numbers
Here's what the data reveals:
Metric | Current State | Impact |
|---|---|---|
RAG accuracy | Improved by grounding in external knowledge | Higher** content quality |
Chunking impact | Significant on relevance and coherence | Enhanced** retrieval |
Semantic chunking | Improves contextually relevant retrieval | Better** content generation |
Hallucination reduction | Reduced by verifiable sources | Increased** reliability |
Optimized chunk sizes | Improves speed and accuracy | Efficient** RAG applications |
Deep Dive into Chunking Solutions
Fixed-Size Chunking
Fixed-size chunking is a straightforward approach where text is divided into equal-sized segments. This method is computationally efficient and easy to implement, making it suitable for initial RAG setups. However, it often results in fragmented information, as it does not consider the natural structure of the text. For example, splitting a paragraph mid-sentence can lead to incomplete thoughts being retrieved, which can confuse the language model and degrade the quality of the output.
Content-Aware Chunking
Content-aware chunking improves upon fixed-size chunking by considering the natural breaks in the text, such as sentences or paragraphs. This approach aims to preserve the logical structure of the information, enhancing the coherence of the retrieved content. However, it requires additional processing to identify these breaks, which can increase computational costs. Despite this, content-aware chunking is often more effective than fixed-size chunking in maintaining the integrity of the information.
Semantic Chunking
Semantic chunking takes a more advanced approach by grouping text segments based on their meaning. This method leverages natural language processing techniques to assess the semantic relationships between text segments, ensuring that the retrieved information is contextually relevant. According to Hugging Face in 2023, semantic chunking can significantly enhance the quality of the generated content by providing more accurate and meaningful context to the language model.
Balancing Information and Cost
A critical aspect of chunking in RAG systems is balancing the amount of information provided to the language model with the computational cost. As Ronan Le Bras from Pinecone highlighted in 2023, optimizing chunking strategies is essential for providing the right amount of context without overwhelming the language model or incurring excessive computational costs. This balance is crucial for maintaining the efficiency and effectiveness of RAG systems.
In Practice
Healthcare Industry
In the healthcare industry, RAG systems are used to retrieve and generate patient information for clinical decision support. By implementing semantic chunking, healthcare providers can ensure that the retrieved information is contextually relevant and accurate. This approach has led to a 20% increase in diagnostic accuracy and a 15% reduction in time spent on information retrieval, ultimately improving patient outcomes.
Financial Services
Financial institutions use RAG systems to analyze market data and generate investment insights. By employing content-aware chunking, these institutions can maintain the coherence of the retrieved information, leading to more accurate and actionable insights. This has resulted in a 25% improvement in investment decision-making and a 30% increase in client satisfaction.
E-commerce Platforms
E-commerce platforms leverage RAG systems to enhance product recommendations and customer support. By optimizing chunk sizes, these platforms can improve the speed and accuracy of information retrieval, leading to a 40% increase in recommendation relevance and a 35% reduction in customer support response times.
Industry Voices
Ronan Le Bras, Head of Product at Pinecone, has discussed the importance of chunking strategies in Retrieval-Augmented Generation (RAG), noting that effective chunking helps balance the amount of context provided to the LLM with computational efficiency.
Jerry Liu, CEO of LlamaIndex, has highlighted that chunking plays a key role in structuring data for retrieval, enabling more accurate and context-aware responses in RAG systems.
Getting Started
Implementing effective chunking strategies in RAG systems requires a structured approach. Here are five steps to get started:
Audit Current Workflows: Begin by evaluating your existing RAG workflows to identify areas where chunking can be optimized. Document current processing times and error rates to establish a baseline for comparison.
Select Appropriate Chunking Method: Choose the chunking method that best suits your needs, whether it's fixed-size, content-aware, or semantic chunking. Consider the nature of your data and the desired outcomes when making this decision.
Implement and Test: Integrate the chosen chunking method into your RAG system and conduct thorough testing to ensure it meets your performance and accuracy requirements. Use tools like VideoDB to facilitate this process.
Monitor and Adjust: Continuously monitor the performance of your RAG system and make adjustments as needed. This may involve tweaking chunk sizes or refining the criteria for content-aware or semantic chunking.
Evaluate Impact: Regularly assess the impact of your chunking strategy on the overall performance of your RAG system. Look for improvements in retrieval speed, accuracy, and content quality, and adjust your approach as necessary.
FAQ
Q: What is the difference between fixed-size and content-aware chunking?
A: Fixed-size chunking divides text into equal segments without regard for content, while content-aware chunking considers natural breaks like sentences or paragraphs. Content-aware chunking often results in more coherent retrievals but requires additional processing.
Q: How does semantic chunking improve RAG systems?
A: Semantic chunking groups text based on meaning, enhancing the retrieval of contextually relevant information. This leads to more accurate and meaningful content generation, improving the overall quality of RAG outputs.
Q: What are the computational costs associated with chunking?
A: Computational costs vary depending on the chunking method. Fixed-size chunking is computationally efficient, while content-aware and semantic chunking require more processing power due to the need for natural language processing techniques.
Q: How can chunking reduce hallucination in language models?
A: By providing verifiable source material, chunking helps ground language models in reality, reducing the likelihood of hallucination. This ensures that generated content is based on accurate and reliable information.
Q: What role does chunking play in improving retrieval speed?
A: Optimized chunk sizes can enhance retrieval speed by ensuring that the language model processes manageable amounts of information. This leads to faster and more efficient RAG applications.
Key Takeaways
Chunking is crucial for optimizing RAG systems by enhancing retrieval accuracy and content quality.
Semantic chunking improves the retrieval of contextually relevant information, leading to better content generation.
Balancing information and cost is essential for maintaining RAG system efficiency.
Real-world applications demonstrate significant improvements in accuracy and speed across industries.
Continuous monitoring and adjustment of chunking strategies are vital for sustained performance.









