Apr 16, 2026
Decoding Video Understanding: Models, Applications, and Future Trends
Explore the world of video understanding models, from action recognition to video captioning. Learn about applications, future trends, and implementation.
Beyond the Pixels: The New Frontier of Video Intelligence
The global video analytics market is on a steep trajectory, projected to hit $14.9 billion by 2026. This explosive growth isn't just about capturing more footage; it's about understanding it. For decades, video has been a passive medium-a digital record we could watch but not easily search, analyze, or query. The vast majority of video data remains unstructured, a massive repository of untapped insights locked away in sequential frames. This presents a significant challenge for organizations across every industry, from media and entertainment to manufacturing and public safety, who are struggling to extract value from their ever-expanding video archives.
The core of this challenge lies in teaching machines to see and interpret the world as humans do. This is the domain of video understanding, a sophisticated field of AI that goes far beyond simple object detection in static images. It involves analyzing the temporal dimension-the sequence, duration, and context of events over time. True video understanding means recognizing not just a person, but a person walking; not just a car, but a car turning left at an intersection. It's about deciphering actions, interactions, and narratives embedded within the flow of pixels, transforming raw video into structured, actionable data.
This transition from passive recording to active intelligence marks a pivotal moment in AI. As deep learning models become more powerful and accessible, we are finally equipping machines with the capability to process and comprehend video content at scale. This unlocks a new class of applications that were previously confined to science fiction, enabling automated systems to monitor complex environments, assist in critical decision-making, and interact with the physical world with unprecedented awareness. The journey into video understanding is not just an academic exercise; it is a commercial and technological imperative for any organization looking to build a competitive edge in a data-driven world.

The Unstructured Data Dilemma: Why Video is Hard
While the promise of video understanding is immense, the technical hurdles are equally significant. Video is arguably the most complex data type, combining spatial information with a temporal dimension, audio streams, and often, embedded text. This multi-modal complexity creates several distinct pain points for developers and data scientists. The first major challenge is temporal context. Unlike a static image, the meaning in a video is often derived from the sequence of events. A model must not only identify objects in each frame but also understand their motion, interaction, and the evolution of the scene over time, which is essential for accurate action recognition.
Second, the sheer scale of video data presents a monumental processing and storage challenge. With the demand for automated video analysis growing rapidly, manual or semi-automated methods are no longer feasible. According to Cognilytica, this surge is driven by the increasing availability of video from sources like IoT devices, drones, and body cameras. Processing thousands of hours of high-resolution video requires immense computational resources and highly efficient pipelines. Without automation, organizations face crippling operational costs and an inability to analyze content in a timely manner, rendering much of their video data useless for real-time applications.
Third, video content is rife with nuance and ambiguity that can easily confuse AI models. Human actions, gestures, and interactions are incredibly subtle and context-dependent. A model must differentiate between a friendly wave and a gesture to stop, or between a person falling accidentally and someone intentionally lying down. This requires models that can reason about context and long-range dependencies within the video, a task that remains a significant research challenge. The consequences of misinterpretation can range from poor user experience in a media application to critical safety failures in an autonomous vehicle.
Finally, the lack of inherent structure makes video notoriously difficult to search and retrieve. Finding a specific ten-second clip within a petabyte-scale archive without descriptive metadata is a near-impossible task. This inefficiency hampers everything from broadcast media, where editors need to find specific archival footage, to law enforcement, where investigators must sift through hours of surveillance video. The inability to quickly access relevant moments translates directly into lost productivity, missed opportunities, and significant delays in critical workflows, highlighting the urgent need for automated indexing and search solutions.
The Architectural Blueprint of Video Understanding
At the heart of modern video understanding are sophisticated deep learning architectures designed to interpret spatio-temporal data. The evolution of these models reflects a journey from adapting image-based techniques to creating novel architectures built specifically for the temporal nature of video. Early approaches often treated video as a sequence of independent images, applying 2D Convolutional Neural Networks (CNNs) to each frame and then aggregating the results. While simple, this method largely ignores the crucial motion and temporal information that defines video content, limiting its effectiveness for complex tasks like action recognition.
From 2D to 3D Convolutions
The first major breakthrough came with the introduction of 3D CNNs. Instead of applying 2D kernels (height x width) to individual frames, models like C3D and I3D use 3D kernels (time x height x width) that convolve across both spatial and temporal dimensions simultaneously. This allows the network to learn features that represent short-term motion patterns directly from the raw pixel data. For example, a 3D convolution can learn to recognize the specific motion of a hand waving or a ball being thrown. This architectural shift marked a significant improvement in performance on action recognition benchmarks and laid the groundwork for more advanced models.
The Rise of Transformers for Long-Range Dependencies
While 3D CNNs excel at capturing local motion, they often struggle to model long-range dependencies-relationships between events that occur far apart in a video. As noted by Google AI in 2022, Transformer-based architectures have become increasingly popular to address this limitation. Originally designed for natural language processing, Transformers use self-attention mechanisms to weigh the importance of all frames relative to each other, regardless of their position in the sequence. Models like TimeSformer and ViViT (Vision Transformer for Video) can effectively capture the narrative structure of a video, making them ideal for tasks like video summarization and complex activity understanding.
Self-Supervised Learning: Training Without Labels
One of the biggest bottlenecks in video understanding is the need for large, manually annotated datasets, which are expensive and time-consuming to create. Self-supervised learning techniques are emerging as a powerful solution. As highlighted by Facebook AI in 2021, methods like contrastive learning allow models to learn meaningful representations from vast amounts of unlabeled video data. For instance, a model can be trained to recognize that two different clips from the same video are more similar to each other than to a clip from a different video. This pre-training process helps the model learn general features about motion and objects, which can then be fine-tuned for specific tasks with much less labeled data. This approach significantly improves the efficiency and scalability of training robust video understanding models, which is critical for platforms like VideoDB that need to handle diverse content.
Video Understanding by the Numbers
Here's what the data reveals about the state and trajectory of the video understanding landscape:
Metric | Statistic | Implication |
|---|---|---|
Market Growth | Projected to reach $14.9 billion by 2026 | Rapid commercial adoption across industries signals a high demand for automated video analysis solutions. |
Model Performance | State-of-the-art results in action recognition & captioning | Deep learning has matured, enabling reliable performance for core video understanding tasks. |
Architectural Shift | Increasing adoption of Transformer-based models | The industry is moving towards architectures that can capture long-range context for more nuanced understanding. |
Training Efficiency | Promising results from self-supervised learning | Reduced dependency on labeled data is making model development faster and more cost-effective. |
Industry Demand | Growing rapidly across diverse sectors | The need for video intelligence is no longer niche, impacting everything from autonomous driving to healthcare. |
Activating Intelligence: Core Capabilities of Modern Models
Modern video understanding systems offer a suite of powerful capabilities that transform raw video into structured, queryable intelligence. These go far beyond simple classification, enabling a granular and contextual analysis of video content. By leveraging these advanced functionalities, organizations can build sophisticated applications that automate complex workflows and unlock new insights from their video data. A comprehensive platform like VideoDB can serve as the backbone for deploying these capabilities at scale, managing everything from data ingestion to model inference.
Granular Action and Activity Recognition
Contemporary models have moved past classifying simple actions like "running" or "jumping." They can now perform granular activity recognition, identifying complex, multi-step actions and the objects involved. For example, instead of just detecting "cooking," a model can identify "slicing vegetables on a cutting board" or "stirring a pot on the stove." In a manufacturing setting, this capability can be used to monitor assembly line workers to ensure procedural compliance and enhance workplace safety by detecting unsafe actions. In sports analytics, it can automatically log specific plays, such as a "three-point shot" in basketball, providing coaches with detailed performance data without manual review.
Dynamic Multi-Object Tracking
Object tracking is the process of locating a moving object (or multiple objects) over time in a video. Modern systems can perform robust multi-object tracking even in crowded scenes with frequent occlusions. This is a cornerstone technology for autonomous driving, where the system must continuously track the position and velocity of surrounding vehicles, pedestrians, and cyclists to navigate safely. In retail analytics, it can be used to analyze shopper behavior, tracking paths through a store to optimize layout and product placement. The ability to maintain a unique ID for each object across frames is critical for understanding interactions and behavior patterns.
Automated Video Captioning and Summarization
One of the most impactful capabilities is the automatic generation of natural language descriptions for video content. Video captioning models can produce human-like sentences that describe the events taking place, such as "A brown dog catches a red frisbee in a grassy park." This is invaluable for improving content accessibility for visually impaired users and for enhancing content discovery. Search engines can index these generated captions, allowing users to find videos by searching for descriptive phrases. For media archives, automated summarization can generate concise text summaries or highlight reels of long-form content, drastically reducing the time needed for manual logging and editing.
This structured output is the ultimate goal of a video understanding pipeline. It converts unstructured pixels into a rich, machine-readable format that can be indexed, queried, and used to power intelligent applications. Systems like VideoDB are designed to store and manage this type of structured data, enabling complex queries over vast video libraries.
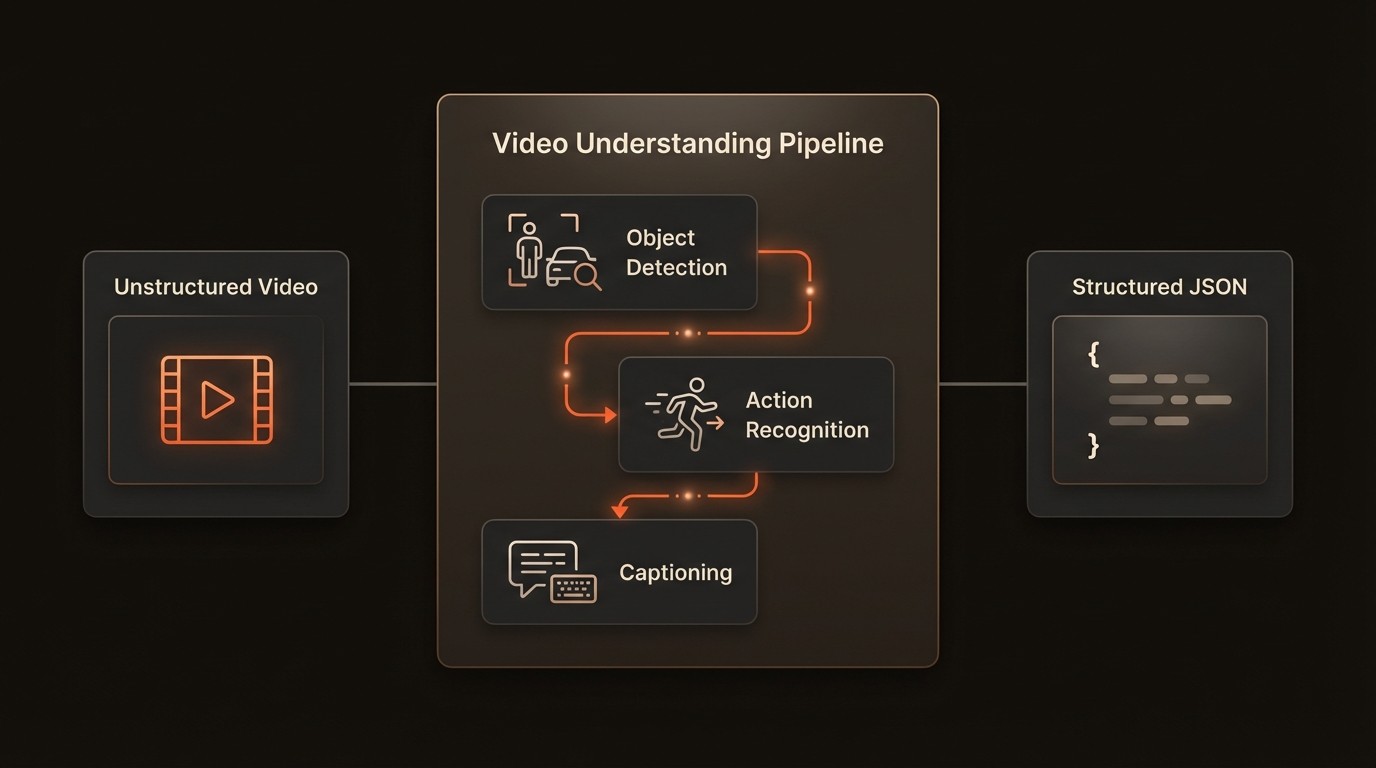
Video Intelligence in Practice
Theoretical capabilities come to life when applied to solve real-world problems. Video understanding models are increasingly being deployed across various industries, delivering tangible value by automating tasks, enhancing safety, and providing data-driven insights. These applications demonstrate the technology's maturity and its readiness for production environments.
Autonomous Systems and Transportation
In the automotive industry, video understanding is the sensory backbone of autonomous vehicles and Advanced Driver-Assistance Systems (ADAS). These systems use a suite of cameras to build a 360-degree view of the environment. AI models continuously analyze these video streams to detect and track other vehicles, pedestrians, cyclists, traffic lights, and lane markings. The implementation involves running highly optimized models on edge hardware within the vehicle to ensure low-latency decision-making. The measurable outcome is enhanced safety, with features like automatic emergency braking and lane-keeping assist directly preventing accidents and saving lives.
Smart Surveillance and Public Safety
Security and surveillance have been transformed by intelligent video analytics. Instead of security personnel manually monitoring dozens of camera feeds, AI-powered systems can automatically detect anomalies and alert operators. For example, a system can be trained to identify unauthorized entry into a restricted area, detect a piece of luggage left unattended for an extended period, or monitor crowd density to prevent overcrowding. In a retail environment, this technology can identify suspicious behavior associated with theft, reducing shrinkage. The outcome is a more proactive security posture, faster response times, and a significant reduction in the manual labor required for monitoring.
Healthcare and Medical Analysis
Video understanding is making significant inroads in healthcare, particularly in surgical training, patient monitoring, and rehabilitation. AI models can analyze recordings of surgical procedures to identify key steps, measure instrument movements, and provide objective feedback to trainee surgeons. In hospitals or assisted living facilities, ambient cameras can monitor patients for falls or signs of distress without intrusive wearable devices. During physical therapy, models can track a patient's range of motion and exercise adherence, providing therapists with quantitative data to track progress. These applications lead to better training outcomes, improved patient safety, and more efficient rehabilitation processes.
Industry Voices on the Future of Visual AI
Fei-Fei Li, Professor of Computer Science at Stanford University, highlighted in a TED Talk that video understanding is a critical step towards enabling machines to interact with the world in a more human-like, ambient way. She emphasized that seeing is not just about identifying objects, but about understanding the relationships, actions, and stories that unfold over time. (2015)
Andrew Zisserman, Professor of Computer Vision at the University of Oxford, has noted that the deep learning revolution has been the primary catalyst for recent progress in video understanding. His work at the Visual Geometry Group has shown how deep architectures have enabled significant leaps in the accuracy of tasks like action recognition and object tracking, moving them from laboratory concepts to practical applications. (2017)
Your Path to Implementing Video Understanding
Adopting video understanding technology requires a structured approach that aligns technical implementation with clear business objectives. It's not just about choosing a model; it's about building a robust pipeline from data ingestion to application integration. Following a clear roadmap can help ensure a successful deployment that delivers measurable value.
Define the Business Case and Success Metrics: Before writing any code, clearly identify the problem you are trying to solve. Is it to reduce manual review time, improve safety compliance, or create a new product feature? Define specific, measurable key performance indicators (KPIs), such as a 50% reduction in manual video tagging time or a 15% increase in the detection rate of safety incidents. This provides a clear target and a way to measure return on investment.
Data Collection and Preparation: The performance of any model is contingent on the quality of the training data. Gather a representative dataset of videos that reflect the real-world conditions in which the model will operate. This includes variations in lighting, camera angles, and subject matter. Proper data labeling and annotation are critical, though self-supervised techniques can help reduce this burden. Ensure your data pipeline is efficient and can handle large video files.
Model Selection and Customization: You can choose between using off-the-shelf pre-trained models, fine-tuning an existing model on your specific data, or building a custom model from scratch. For many applications, fine-tuning a pre-trained model offers the best balance of performance and development effort. Platforms like VideoDB can simplify this process by providing tools to manage models and datasets, allowing you to experiment and find the optimal approach for your use case.
Develop a Scalable Infrastructure: Video processing is computationally intensive. Plan your deployment infrastructure to handle the required throughput and latency. This may involve using cloud-based GPU instances for training and a combination of cloud or edge devices for inference, depending on the application's real-time requirements. Ensure your architecture is designed to scale as your video volume and processing needs grow over time.
Integrate, Monitor, and Iterate: The final step is to integrate the model's output into your target application or business workflow via an API. Deployment is not the end of the journey. Continuously monitor the model's performance in production to detect concept drift or performance degradation. Establish a feedback loop where misclassifications or new scenarios can be used to retrain and improve the model over time, ensuring its long-term accuracy and relevance.
Common Questions About Video Understanding
Q: What is the difference between video understanding and traditional video analytics?
A: Traditional video analytics typically relies on rule-based algorithms for specific tasks like motion detection or object counting. Video understanding, powered by deep learning, aims for a more holistic comprehension of content. It focuses on recognizing complex actions, understanding the context of events, and generating descriptive, human-like insights rather than just flagging predefined events.
Q: How much data is needed to train a custom video understanding model?
A: The amount of data required varies significantly based on the task's complexity and the desired accuracy. For fine-tuning a pre-trained model for a specific action, a few hundred labeled video clips may be sufficient. However, training a complex model from scratch can require tens of thousands of hours of video. The use of self-supervised learning and data augmentation can help reduce these requirements.
Q: Are Transformer models always better than CNNs for video?
A: Not necessarily. Transformers excel at capturing long-range temporal dependencies, making them ideal for understanding complex narratives or activities that unfold over long periods. However, 3D CNNs are often more computationally efficient and can be highly effective for recognizing short, distinct actions. The best choice often involves a hybrid approach or depends on the specific application's latency and accuracy requirements.
Q: What are the biggest challenges in deploying these models in production?
A: The primary challenges include managing the high computational cost of video processing, ensuring low latency for real-time applications, and handling the vast diversity of real-world video data. Another significant hurdle is model maintenance, which involves monitoring for performance degradation over time (concept drift) and having a robust pipeline for retraining and redeploying updated models without service interruption.
Q: How does a system like VideoDB fit into a video understanding pipeline?
A: VideoDB acts as a specialized database and infrastructure layer designed for video data. It sits at the core of the pipeline, managing the storage of raw video and the structured data generated by understanding models. It enables efficient, multi-modal search across vast video archives by indexing detected objects, actions, and generated text. This allows developers to build applications that can perform complex queries on video content without having to build the underlying data management infrastructure from scratch.
Key Takeaways
The video analytics market is projected to reach $14.9 billion by 2026, driven by the need for automated video analysis.
Modern video understanding relies on advanced deep learning architectures like 3D CNNs and Transformers to interpret complex spatio-temporal data.
Key capabilities include granular action recognition, dynamic object tracking, and automated video captioning, which turn unstructured video into actionable data.
Real-world applications are already creating value in industries like autonomous driving, surveillance, and healthcare.
Successful implementation requires a structured approach, from defining a clear business case to building a scalable infrastructure and establishing a continuous feedback loop for model improvement.









