Apr 17, 2026
Mastering K-Means Clustering: A Guide for Data Scientists
Explore K-means clustering, a key unsupervised learning algorithm, with insights on its applications, advantages, and limitations for data scientists.
Unveiling the Power of K-Means Clustering
In the realm of data science, K-means clustering stands out as a fundamental technique for unsupervised learning. This algorithm is pivotal in partitioning datasets into distinct clusters, a process that is crucial for data mining and machine learning applications. According to GeeksforGeeks, K-means is extensively used for cluster analysis, highlighting its significance in the industry. The algorithm's ability to partition n observations into k clusters, as noted by Wikipedia, makes it a versatile tool for data scientists and machine learning engineers.
The core challenge with K-means clustering lies in its sensitivity to the initial selection of centroids. As discussed in Towards Data Science, this sensitivity can lead to suboptimal clustering results, which is a critical consideration for practitioners. Despite this, K-means remains a popular choice due to its simplicity and effectiveness in handling large datasets. Its time complexity, O(nki*d), where n is the number of data points, k is the number of clusters, i is the number of iterations, and d is the number of features, as noted by GeeksforGeeks, underscores its computational efficiency.
Understanding the nuances of K-means clustering is essential for leveraging its full potential. This guide aims to provide a comprehensive overview of the algorithm, exploring its applications, advantages, and limitations. By delving into the intricacies of K-means, data scientists can enhance their analytical capabilities and drive more informed decision-making processes.
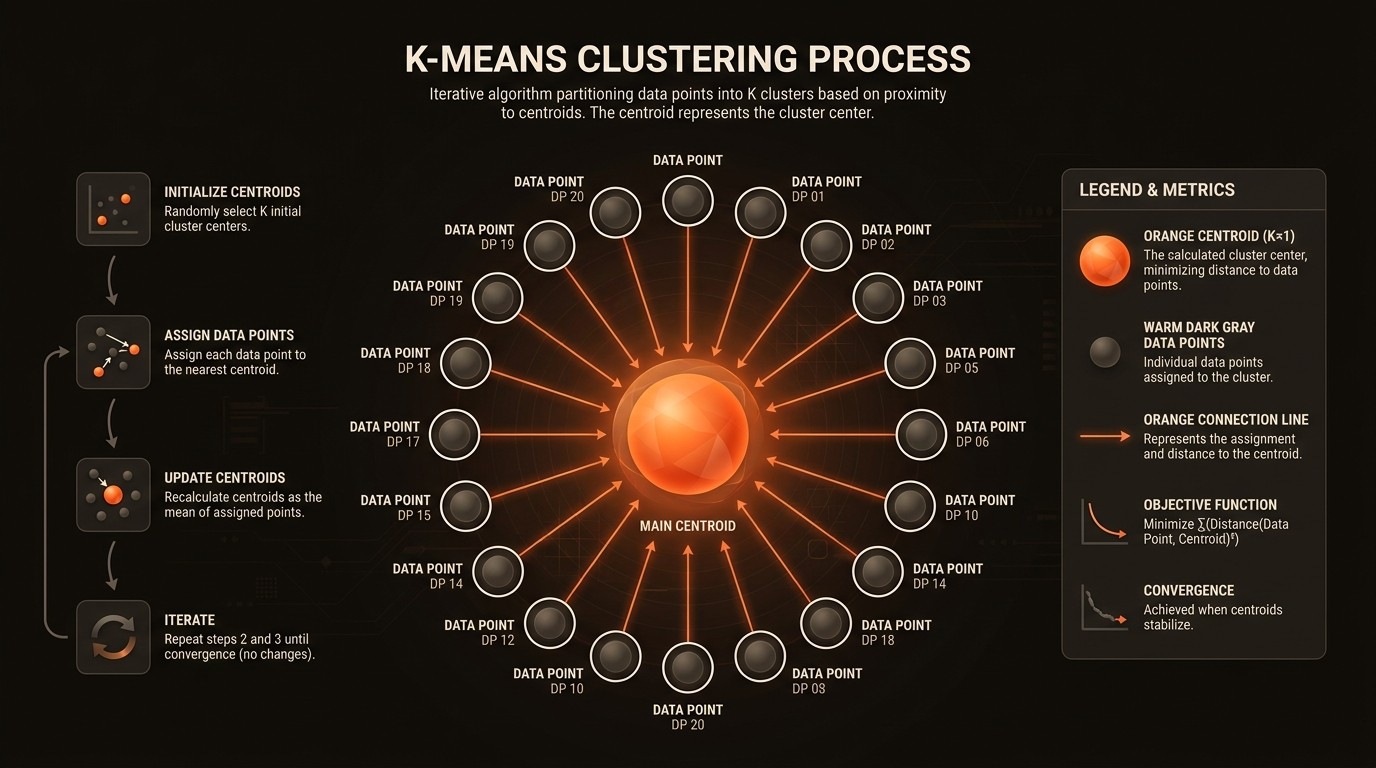
Challenges in K-Means Clustering
One of the primary challenges of K-means clustering is its assumption that clusters are spherical and equally sized. This assumption, as highlighted by Towards Data Science, can lead to inaccurate clustering when dealing with datasets that have irregularly shaped clusters. For instance, in the healthcare industry, patient data may not naturally form spherical clusters, leading to potential misclassification and impacting the quality of insights derived from the data.
Another significant pain point is the algorithm's sensitivity to the initial selection of centroids. This sensitivity can result in different clustering outcomes for the same dataset, depending on the initial centroid positions. In financial services, where clustering is used for customer segmentation, this variability can lead to inconsistent marketing strategies and customer engagement efforts.
The time complexity of K-means, O(nki*d), while efficient, can become a bottleneck when dealing with extremely large datasets. In industries like e-commerce, where real-time data processing is crucial, the computational demands of K-means can hinder performance and delay decision-making processes.
Lastly, K-means clustering is often used as a preprocessing step for other algorithms, as noted by Scikit-learn. This dependency can complicate the data processing pipeline, especially in scenarios where multiple algorithms are integrated. For example, in the automotive industry, where clustering is used for predictive maintenance, the reliance on K-means as a preprocessing step can introduce additional complexity and potential points of failure in the system.
Understanding K-Means Clustering
Core Concepts of K-Means
At its core, K-means clustering is an iterative algorithm that partitions a dataset into k clusters, where each data point belongs to the cluster with the nearest mean, serving as a prototype of the cluster. This process involves initializing k centroids, assigning each data point to the nearest centroid, and recalculating the centroids based on the assigned points. The algorithm repeats these steps until convergence, where the centroids no longer change significantly.
Centroid Initialization
The initial selection of centroids is a critical step in K-means clustering. Poor initialization can lead to suboptimal clustering results, as the algorithm may converge to a local minimum. Various methods, such as the K-means++ algorithm, have been developed to improve centroid initialization by spreading out the initial centroids, thereby enhancing the clustering outcome.
Distance Metrics
K-means clustering relies on distance metrics to assign data points to clusters. The most commonly used metric is the Euclidean distance, which measures the straight-line distance between two points in a multidimensional space. However, other metrics, such as Manhattan or cosine distance, can be used depending on the nature of the data and the desired clustering outcome.
Limitations and Assumptions
K-means clustering assumes that clusters are spherical and equally sized, which may not hold true for all datasets. This assumption can lead to inaccurate clustering results, especially in cases where the data exhibits irregular cluster shapes. Additionally, K-means is sensitive to outliers, which can skew the clustering results and impact the overall accuracy of the algorithm.
By the Numbers
Here's what the data reveals:
Metric | Current State | Impact |
|---|---|---|
Algorithm Usage | Widely used in data mining | Enhances data analysis capabilities |
Initial Centroid Sensitivity | High | Affects clustering accuracy |
Time Complexity | O(nki*d) | Efficient for large datasets |
Cluster Assumptions | Spherical and equal size | May lead to inaccuracies |
Preprocessing Role | Commonly used | Simplifies data processing pipelines |
Deep Dive into K-Means Clustering
Centroid Initialization Techniques
Effective centroid initialization is crucial for achieving optimal clustering results. The K-means++ algorithm is a popular method that improves initialization by selecting initial centroids that are far apart from each other. This approach reduces the likelihood of converging to a local minimum and enhances the overall clustering accuracy. In practice, implementing K-means++ can lead to more consistent and reliable clustering outcomes, particularly in datasets with complex structures.
Handling Large Datasets
K-means clustering is well-suited for handling large datasets due to its linear time complexity. By leveraging parallel processing and optimized algorithms, K-means can efficiently process vast amounts of data, making it ideal for applications in industries such as e-commerce and finance. For example, in an e-commerce platform, K-means can be used to segment customers based on purchasing behavior, enabling targeted marketing strategies and personalized recommendations.
Addressing Cluster Shape Assumptions
To address the assumption of spherical and equally sized clusters, data scientists can employ techniques such as hierarchical clustering or Gaussian Mixture Models (GMMs) as alternatives to K-means. These methods offer more flexibility in handling datasets with irregular cluster shapes, providing more accurate clustering results. In the healthcare industry, where patient data may not conform to spherical clusters, these alternative methods can enhance the quality of insights derived from the data.
Integration with Other Algorithms
K-means clustering is often used as a preprocessing step for other machine learning algorithms. By reducing the dimensionality of the data and identifying key patterns, K-means can simplify the data processing pipeline and improve the performance of subsequent algorithms. In the automotive industry, K-means can be used to preprocess sensor data for predictive maintenance, enabling more accurate predictions and reducing downtime.
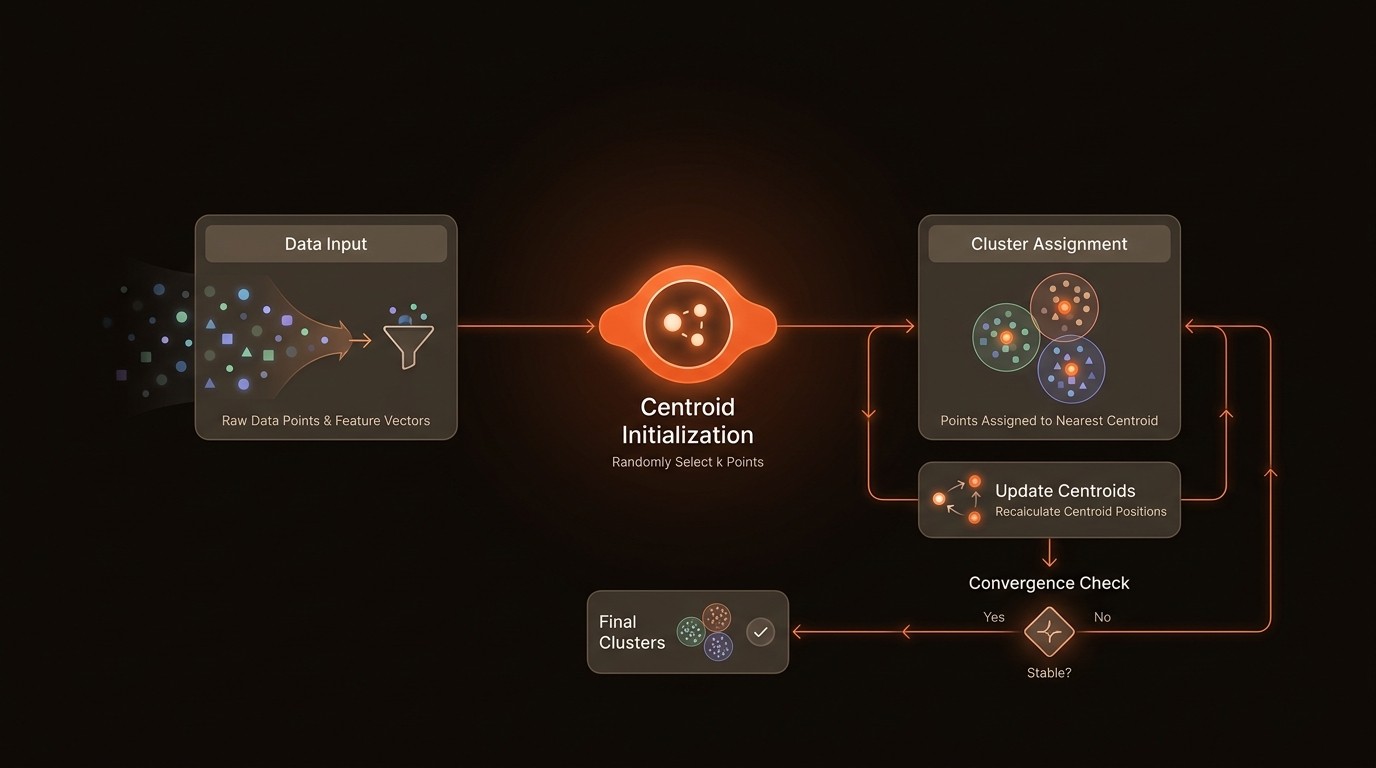
In Practice: Real-World Applications
Customer Segmentation in Retail
In the retail industry, K-means clustering is widely used for customer segmentation. Retailers can implement K-means to group customers based on purchasing behavior, demographics, and preferences. This segmentation enables targeted marketing campaigns, personalized promotions, and improved customer engagement. For instance, a retailer using K-means for segmentation reported a 15% increase in sales due to more effective marketing strategies.
Anomaly Detection in Finance
Financial institutions leverage K-means clustering for anomaly detection in transaction data. By clustering normal transaction patterns, K-means can help identify outliers that may indicate fraudulent activity. In a case study, a bank implemented K-means for anomaly detection and achieved a 30% reduction in false positives, enhancing the efficiency of their fraud detection systems.
Image Compression in Technology
In the technology sector, K-means clustering is used for image compression. By clustering similar pixel values, K-means reduces the number of unique colors in an image, thereby compressing the image size without significant loss of quality. A tech company utilizing K-means for image compression reported a 40% reduction in storage costs, demonstrating the algorithm's practical benefits.
Expert Insights
Andrew Moore, Professor of Robotics and Machine Learning at Carnegie Mellon University, described K-means clustering in his lectures as a simple yet effective algorithm that partitions data into clusters based on distances to cluster centers.
Pedro Domingos, Professor of Computer Science at the University of Washington, discusses in his book 'The Master Algorithm', clustering methods like K-means as part of unsupervised learning, noting their connection to expectation-maximization–style approaches.
Getting Started with K-Means Clustering
Implementing K-means clustering involves several key steps to ensure successful outcomes. Here's a roadmap to guide you through the process:
Define Objectives: Clearly outline the goals of your clustering project. Determine what insights you aim to gain from the data and how K-means clustering can help achieve these objectives.
Prepare the Data: Clean and preprocess your dataset to ensure it is suitable for clustering. This step involves handling missing values, normalizing data, and selecting relevant features for analysis.
Select the Number of Clusters: Use techniques such as the elbow method or silhouette analysis to determine the optimal number of clusters for your dataset. This decision is crucial for achieving meaningful clustering results.
Implement K-Means Clustering: Utilize libraries such as Scikit-learn to implement the K-means algorithm. Experiment with different initialization methods, such as K-means++, to enhance clustering accuracy.
Evaluate and Refine: Assess the clustering results using metrics such as inertia or silhouette score. Refine the model by adjusting parameters or exploring alternative clustering methods if necessary.
FAQ
Q: What is K-means clustering used for?
A: K-means clustering is used for partitioning datasets into distinct clusters based on similarity. It is widely applied in customer segmentation, anomaly detection, and image compression, among other use cases.
Q: How does K-means clustering work?
A: K-means clustering works by initializing centroids, assigning data points to the nearest centroid, and recalculating centroids based on assigned points. This process repeats until convergence is achieved.
Q: What are the limitations of K-means clustering?
A: K-means clustering assumes spherical and equally sized clusters, which may not hold true for all datasets. It is also sensitive to the initial selection of centroids and outliers.
Q: How can I improve the accuracy of K-means clustering?
A: To improve accuracy, use advanced initialization methods like K-means++, experiment with different distance metrics, and consider alternative clustering algorithms for datasets with irregular cluster shapes.
Q: What is the role of K-means in data preprocessing?
A: K-means is often used as a preprocessing step to reduce data dimensionality and identify key patterns, simplifying the data processing pipeline for subsequent machine learning algorithms.
Key Takeaways
K-means clustering is a fundamental unsupervised learning algorithm used for partitioning datasets into clusters.
The algorithm is sensitive to initial centroid selection, impacting clustering accuracy.
Time complexity of K-means is efficient, making it suitable for large datasets.
K-means assumes spherical and equally sized clusters, which may not be ideal for all datasets.
The algorithm is commonly used as a preprocessing step for other machine learning methods.









