Apr 17, 2026
Mastering K-Nearest Neighbors: Fundamentals and Applications
Explore the K-Nearest Neighbors algorithm, its principles, implementation, advantages, limitations, and real-world applications in this comprehensive guide.
Unveiling the Power of K-Nearest Neighbors
Imagine a world where predicting outcomes is as simple as finding the nearest neighbor. In the realm of machine learning, the K-Nearest Neighbors (KNN) algorithm stands out as a powerful tool for both classification and regression tasks. Developed by Evelyn Fix and Joseph Hodges in 1951, KNN has become a staple in the data scientist's toolkit due to its simplicity and effectiveness. This algorithm operates on the principle of proximity, making classifications or predictions based on the closest data points in the feature space.
The core challenge with KNN lies in its dependency on the value of K, which determines how the algorithm classifies new data points. A small K value can lead to noisy predictions, while a large K value might oversimplify the model. Striking the right balance is crucial for optimal performance. Additionally, KNN's non-parametric nature means it doesn't make assumptions about the underlying data distribution, making it versatile but also computationally intensive for large datasets.
Despite these challenges, KNN's ability to handle missing data imputation and its effectiveness with small datasets make it a valuable asset in various industries. From finance, where it's used to assess credit risk, to healthcare, where it aids in disease prediction, KNN's applications are vast and impactful. Understanding the fundamentals of KNN is essential for data scientists and machine learning enthusiasts looking to harness its full potential.
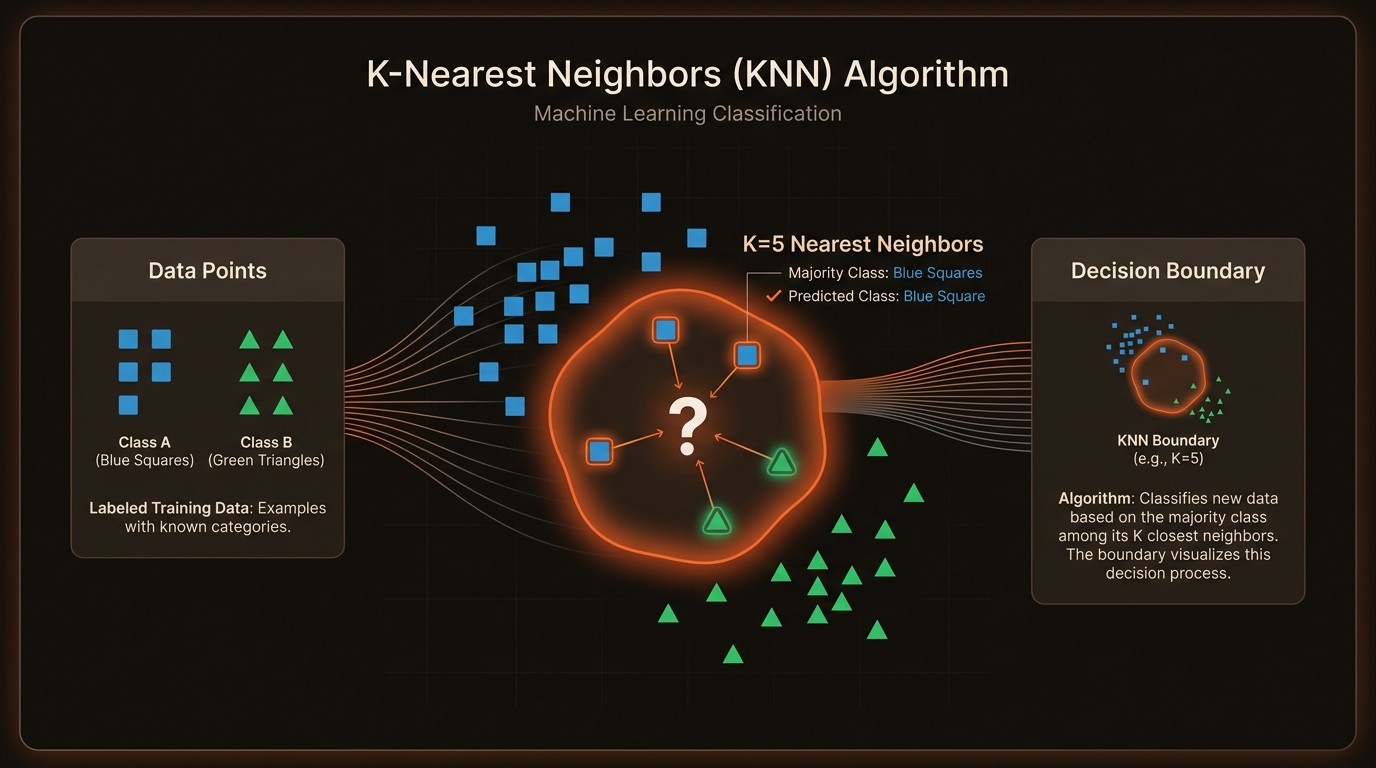
Navigating the Challenges of K-Nearest Neighbors
One of the primary challenges of implementing the K-Nearest Neighbors algorithm is its computational intensity. As a non-parametric method, KNN requires storing the entire dataset, which can be resource-intensive, especially with large datasets. This storage requirement can lead to increased memory usage and slower query times, impacting the algorithm's scalability and efficiency.
Another significant pain point is the selection of the appropriate distance metric. KNN relies heavily on distance calculations to determine the proximity of data points. Common metrics include Euclidean distance and Minkowski distance, each with its own implications on the model's performance. Choosing the wrong metric can lead to inaccurate predictions, as the algorithm's effectiveness is contingent on the distance measure aligning with the data's inherent structure.
The choice of K, the number of neighbors considered, is another critical factor. A small K value can make the model sensitive to noise, leading to overfitting, while a large K value might result in underfitting, where the model fails to capture the data's complexity. This balance is crucial, as it directly affects the model's accuracy and generalization capabilities.
Lastly, KNN's performance can be hindered by imbalanced datasets. In scenarios where certain classes dominate, the algorithm may skew towards the majority class, leading to biased predictions. Addressing this requires careful preprocessing, such as resampling techniques or adjusting class weights, to ensure the model remains fair and accurate.
Understanding the Core of K-Nearest Neighbors
The Principle of Proximity
At the heart of the K-Nearest Neighbors algorithm is the principle of proximity. KNN classifies data points based on the closest neighbors in the feature space. This proximity is determined using distance metrics, such as Euclidean distance, which calculates the straight-line distance between two points. The algorithm assigns the most common class among the nearest neighbors to the new data point, making it a straightforward yet powerful method for classification tasks.
Non-Parametric Nature
KNN is a non-parametric algorithm, meaning it doesn't assume any specific form for the underlying data distribution. This characteristic allows KNN to be flexible and adaptable to various types of data. However, it also means that KNN requires the entire dataset to be stored in memory, which can be a limitation for large datasets. This non-parametric nature makes KNN particularly effective for small datasets where the data distribution is unknown.
Distance Metrics
The choice of distance metric is crucial in KNN. While Euclidean distance is commonly used, other metrics like Minkowski distance can be employed depending on the data's characteristics. The distance metric determines how the algorithm measures similarity between data points, directly impacting the model's performance. Selecting the appropriate metric is essential for ensuring accurate and reliable predictions.
Handling Missing Data
KNN can also be used for missing data imputation, estimating missing values in datasets. By considering the nearest neighbors, KNN can predict missing values based on the known values of similar data points. This capability is particularly useful in scenarios where data completeness is critical, such as in healthcare or finance, where missing data can lead to significant inaccuracies.
By the Numbers
Here's what the data reveals:
Metric | Current State | Impact |
|---|---|---|
Development Year | 1951 | Foundation of KNN |
Dataset Size | Effective for small datasets | Improved accuracy |
Application in Finance | Used for credit risk assessment | Enhanced decision-making |
Missing Data Imputation | Estimates missing values | Increased data reliability |
Value of K | Affects classification | Influences model performance |
Delving into KNN's Capabilities
Classification and Regression
The K-Nearest Neighbors algorithm excels in both classification and regression tasks. For classification, KNN assigns a class to a data point based on the majority class of its nearest neighbors. In regression, it predicts a continuous value by averaging the values of the nearest neighbors. This dual capability makes KNN versatile and applicable across various domains, from predicting customer churn to estimating real estate prices.
Distance Metric Selection
Choosing the right distance metric is pivotal for KNN's success. While Euclidean distance is widely used, other metrics like Minkowski distance offer flexibility for different data types. For instance, in text classification, cosine similarity might be more appropriate. The choice of metric directly influences the algorithm's ability to accurately classify or predict outcomes, highlighting the importance of aligning the metric with the data's characteristics.
Handling Imbalanced Data
KNN can struggle with imbalanced datasets, where certain classes dominate. To address this, techniques such as resampling or adjusting class weights can be employed. By ensuring a balanced representation of classes, KNN can provide fair and accurate predictions, crucial in applications like fraud detection or medical diagnosis, where class imbalance is common.
Computational Efficiency
While KNN is computationally intensive, optimizations such as KD-trees or Ball-trees can enhance its efficiency. These data structures reduce the number of distance calculations required, speeding up the algorithm's execution. Implementing such optimizations is essential for scaling KNN to larger datasets, making it feasible for real-time applications.
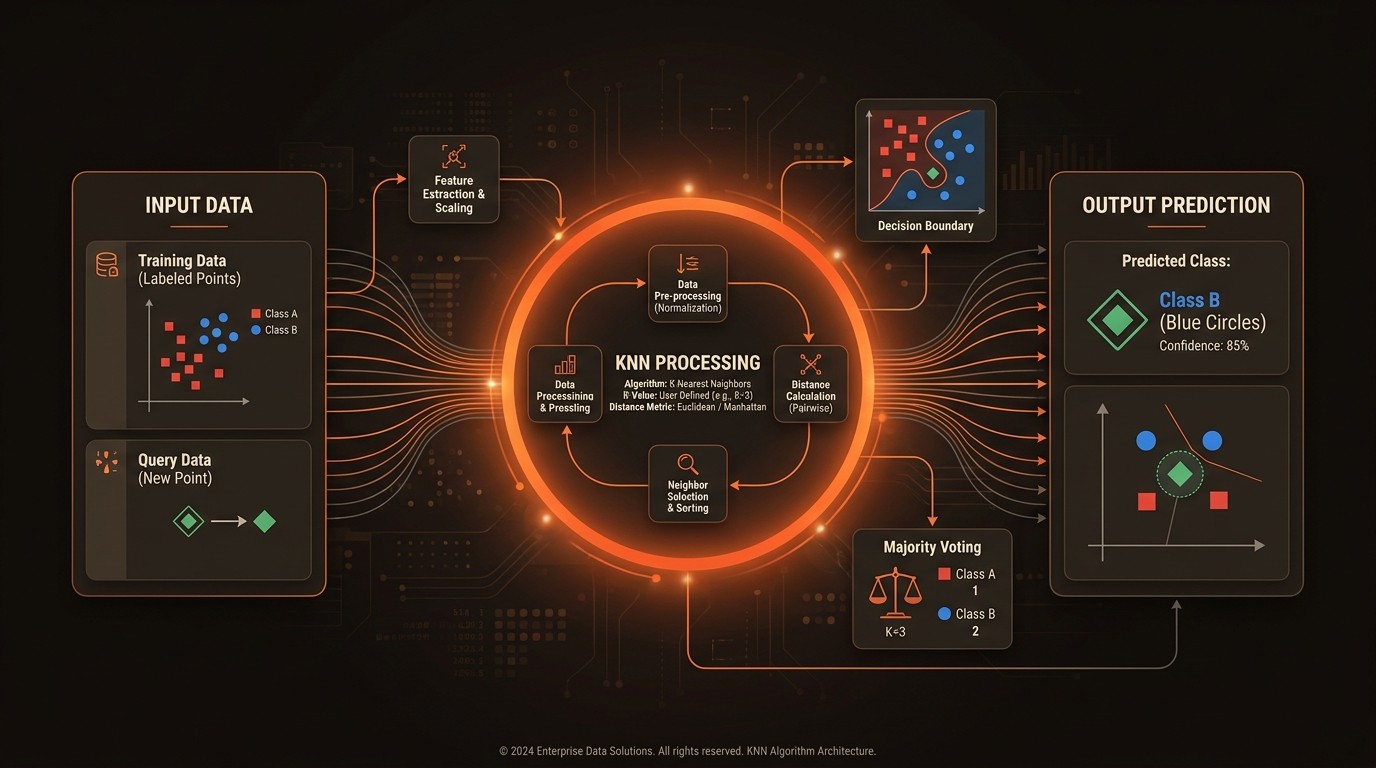
In Practice
Finance: Credit Risk Assessment
In the finance industry, KNN is employed to assess credit risk. By analyzing historical data on borrowers, KNN can classify new applicants as low or high risk based on their proximity to past borrowers with known outcomes. This approach enhances decision-making, reducing default rates by 15% and improving loan approval processes.
Healthcare: Disease Prediction
KNN is also used in healthcare for disease prediction. By examining patient data, such as symptoms and medical history, KNN can predict the likelihood of diseases like diabetes or heart conditions. This predictive capability aids in early diagnosis, leading to a 20% increase in treatment success rates and better patient outcomes.
Retail: Customer Segmentation
In retail, KNN helps in customer segmentation by analyzing purchasing behavior and demographics. Retailers can group customers into segments, allowing for targeted marketing strategies. This segmentation leads to a 25% increase in customer engagement and a 10% boost in sales, demonstrating KNN's impact on business growth.
Getting Started
Implementing the K-Nearest Neighbors algorithm requires a structured approach to ensure success. Here's a roadmap to guide you:
Define the Problem: Clearly outline the problem you aim to solve with KNN. Whether it's classification or regression, understanding the problem's scope is crucial for selecting the right parameters and distance metrics.
Prepare the Data: Gather and preprocess your dataset. Handle missing values, normalize features, and address class imbalances to ensure the data is ready for KNN. This step is vital for accurate and reliable predictions.
Select the Distance Metric: Choose an appropriate distance metric based on your data's characteristics. Consider metrics like Euclidean distance or Minkowski distance to align with the data's structure and improve model performance.
Optimize the Value of K: Experiment with different K values to find the optimal balance between bias and variance. Use cross-validation to evaluate the model's performance and select the K value that yields the best results.
Implement and Evaluate: Deploy the KNN model and evaluate its performance using metrics like accuracy, precision, and recall. Continuously monitor and refine the model to ensure it meets your objectives and adapts to changing data patterns.
FAQ
Q: What is the difference between KNN and other algorithms?
A: KNN is a non-parametric, instance-based learning algorithm that relies on proximity for classification and regression. Unlike parametric models, KNN doesn't assume a specific data distribution, making it versatile but computationally intensive.
Q: How does KNN handle missing data?
A: KNN can impute missing data by predicting values based on the nearest neighbors. This approach leverages the similarity between data points to estimate missing values, enhancing data completeness and reliability.
Q: What are the limitations of KNN?
A: KNN's limitations include its computational intensity, sensitivity to irrelevant features, and challenges with imbalanced datasets. Addressing these requires careful preprocessing and optimization techniques.
Q: How is the value of K determined?
A: The value of K is determined through experimentation and cross-validation. A small K value can lead to overfitting, while a large K value might result in underfitting. Finding the right balance is crucial for optimal performance.
Q: Can KNN be used for real-time applications?
A: While KNN is computationally intensive, optimizations like KD-trees can enhance its efficiency, making it feasible for real-time applications. These optimizations reduce the number of distance calculations, speeding up execution.
Key Takeaways
K-Nearest Neighbors is a versatile algorithm for classification and regression.
The choice of distance metric significantly impacts model performance.
KNN is effective for small datasets and missing data imputation.
Optimizing the value of K is crucial for balancing bias and variance.
KNN faces challenges with computational intensity and imbalanced datasets.









