Apr 16, 2026
Long-Context Video Analysis: From Raw Footage to Actionable AI Insights
Explore how AI and deep learning unlock insights from long-context video. A technical guide for researchers and engineers on advanced video understanding.
Beyond the Frame: The Untapped Potential of Long-Form Video
According to a 2020 report from Deloitte, approximately 80% of all video data remains unanalyzed. This staggering figure represents a vast, dark archive of untapped information. For decades, video analysis has largely focused on short clips or individual frames-identifying an object, recognizing a face, or classifying a simple action. While useful, this approach misses the most valuable element of video: context. The true narrative of an event, the subtle buildup to a critical failure on a manufacturing line, or the complex customer journey through a retail space isn't contained in a single frame. It unfolds over minutes, hours, or even days.
This is the core challenge that long-context video analysis aims to solve. It represents a paradigm shift from isolated event detection to comprehensive temporal understanding. By leveraging advanced AI and deep learning models, we can now process and interpret extended video sequences, connecting disparate moments to uncover patterns, predict outcomes, and generate actionable insights that were previously impossible to extract. This capability moves beyond simple tagging and into the realm of genuine video intelligence, where the system understands the 'why' behind the 'what'. The demand for this technology is surging, with the overall video analytics market projected to hit $14.9 billion by 2026.
The transition is not just about processing more data; it's about processing it more intelligently. Traditional methods falter when faced with the sheer scale and complexity of continuous video streams. They lack the architectural sophistication to maintain state, track object interactions over time, or comprehend causal relationships. Modern deep learning techniques, particularly those involving transformers and recurrent neural networks, are purpose-built to model these long-range dependencies. They empower systems to learn the normal rhythm of an environment and instantly flag subtle deviations, transforming passive video feeds into proactive, intelligent sensors for any business process.

The High Cost of Unstructured Video Data
Failing to analyze long-form video isn't just a missed opportunity; it's a significant operational drag with tangible costs. The inability to efficiently process this data introduces critical bottlenecks and blind spots across industries. For technical leaders and engineers, these challenges manifest as four distinct pain points that directly impact efficiency, security, and innovation. Each problem underscores why a new approach is not just beneficial but essential for staying competitive in a data-driven landscape where visual information is paramount.
First, the sheer information overload makes manual review completely unfeasible. An organization with hundreds of cameras generates petabytes of data annually. Relying on human operators to sift through this footage to find a specific incident or pattern is economically and logistically impossible. This leads to the vast majority of video being archived without ever yielding its insights, representing a massive sunk cost in storage and infrastructure. The consequence is reactive problem-solving, where incidents are investigated after the fact rather than being prevented proactively through pattern detection.
Second, conventional analysis tools suffer from a critical loss of temporal context. A system that analyzes video in five-second chunks might detect a person entering a restricted area, but it will miss the preceding thirty minutes of suspicious behavior that led up to the breach. In manufacturing, it might flag a final product defect but fail to identify the subtle, multi-stage machine calibration drift that caused it. This lack of long-term memory means that root cause analysis remains a manual, time-consuming process, and predictive maintenance or security remains out of reach.
Third, legacy video processing systems create severe scalability and latency bottlenecks. They are often built on monolithic architectures that cannot handle the concurrent ingestion and analysis of thousands of high-resolution streams. As an organization's video sources grow, these systems buckle, leading to processing delays, dropped frames, and an inability to generate real-time alerts. For applications in public safety, logistics, or industrial monitoring, this latency isn't just an inconvenience-it's a critical failure that can have severe financial or safety consequences.
Finally, the inefficiency of search and retrieval in large video archives is a major productivity killer. Finding a specific event without precise timestamps is like searching for a needle in a digital haystack. A query like "find all instances where a forklift came within five feet of a pedestrian in warehouse B last month" is impossible for systems that rely on manual tags or basic metadata. Engineers and analysts waste countless hours scrubbing through timelines, a low-value task that directly inhibits their ability to work on strategic initiatives and innovation.
The Architectural Pillars of Video Intelligence
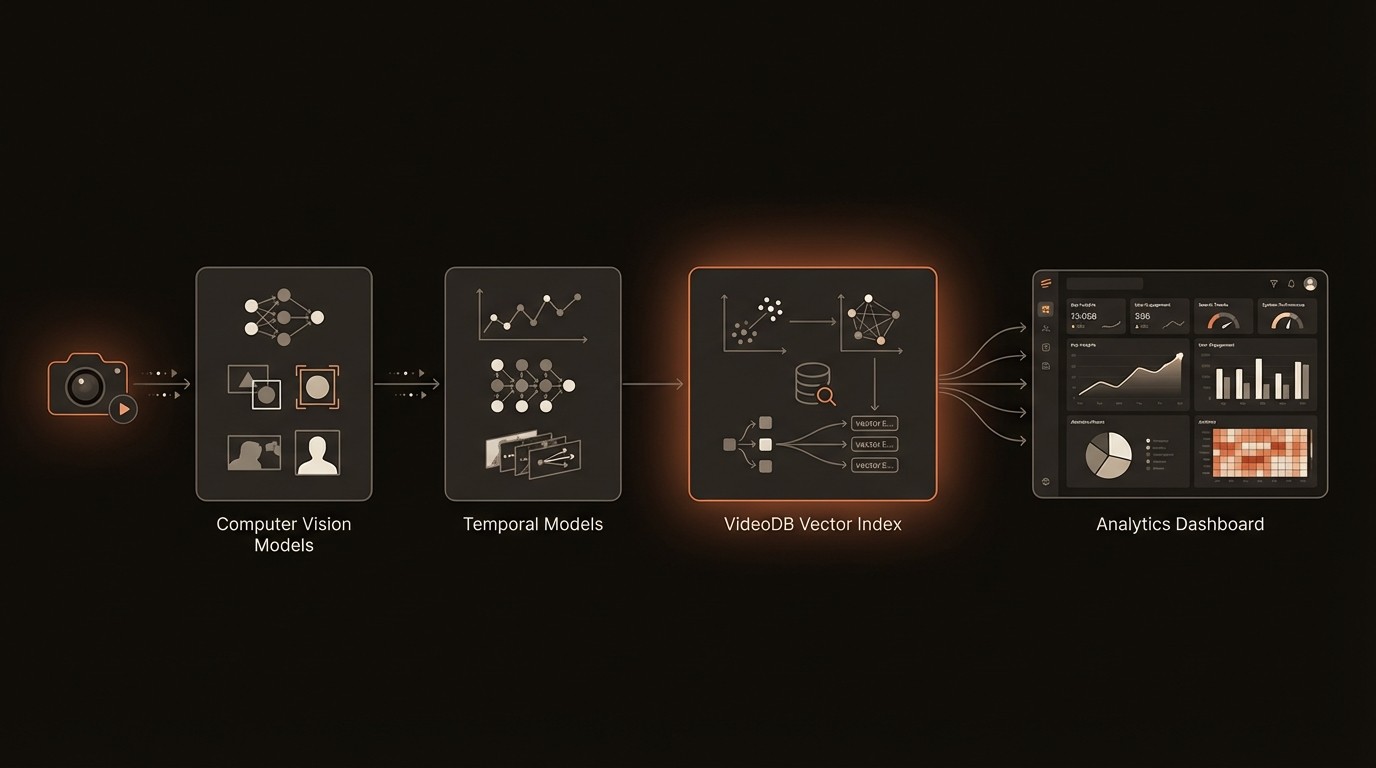
To overcome the challenges of long-context analysis, we need to move beyond traditional computer vision techniques and embrace a more sophisticated, multi-layered architecture. This modern stack combines perception, temporal modeling, and efficient indexing to transform raw pixel streams into a queryable, intelligent database. Understanding these core components is crucial for any engineer or researcher looking to build or deploy effective video analysis solutions. Each layer builds upon the last, creating a pipeline that can comprehend not just moments, but entire narratives within video data.
From Pixels to Semantics: The Role of Computer Vision
The foundational layer is computer vision, which handles the initial perception task. This involves applying deep learning models to individual frames or short clips to extract basic semantic information. Core tasks include object detection (identifying and locating objects like people, vehicles, or equipment), action recognition (classifying simple actions like 'walking' or 'lifting'), and scene classification (understanding the environment, such as 'warehouse' or 'office'). These models, often Convolutional Neural Networks (CNNs) or Vision Transformers (ViTs), act as the eyes of the system, converting unstructured pixel data into a stream of structured metadata-for example, (timestamp, frame_id, object_id, class, bounding_box).
Weaving the Narrative: Temporal Modeling with Deep Learning
Once we have frame-level semantics, the next challenge is to understand how they connect over time. This is where temporal modeling comes in. Techniques like Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, and more recently, Temporal Transformers, are designed to process sequences of data. They analyze the stream of metadata from the computer vision layer to identify long-range dependencies and complex events. For instance, a temporal model can learn that the sequence of events (person_approaches_machine, machine_door_opens, person_reaches_inside, machine_door_closes) constitutes a 'maintenance check' event. This layer is what provides the 'context' in long-context analysis, moving from recognizing objects to understanding behaviors and processes.
Indexing for Speed: The Rise of Vector Databases
Extracting these complex events is only half the battle. To make them useful, they must be searchable at scale. This is where vector databases become critical. Each detected event, action, or even the overall content of a video segment can be encoded into a high-dimensional vector embedding by a deep learning model. These embeddings capture the semantic meaning of the content. A specialized database, such as VideoDB, is designed to index billions of these vectors for incredibly fast similarity search. This allows for powerful semantic queries that go far beyond simple keywords. Instead of searching for the tag 'car', you can provide an image of a specific car and find all video clips containing similar vehicles, or search using natural language. A conceptual query might look like this:
This three-layer architecture-perception, temporal modeling, and vector indexing-forms the backbone of any modern long-context video analysis system. It creates a robust pipeline for transforming massive, unstructured video archives into a source of structured, queryable, and actionable intelligence.
By the Numbers: The Video Analytics Landscape
Here's what the data reveals about the rapid growth and significant opportunities within the AI-powered video analysis market:
Metric | Statistic | Implication for Long-Context Analysis |
|---|---|---|
Market Growth Projection | $14.9 billion by 2026 | Indicates strong commercial demand and investment in advanced video intelligence solutions. |
AI Adoption Rate (CAGR) | 29.2% | Highlights the rapid shift from traditional surveillance to AI-driven analytics for operational insights. |
Unanalyzed Video Data | ~80% of all video | Represents a massive, untapped resource that long-context solutions are uniquely positioned to unlock. |
Cloud-Based Solution Growth | Expected to grow rapidly | Scalability and cost-effectiveness of cloud platforms are key enablers for processing large video archives. |
Deep Learning Performance | State-of-the-art results | Continuous model improvements are making it possible to analyze more complex and subtle events over longer durations. |
Building an Intelligent Video Analysis Pipeline
Moving from theory to practice requires building a robust pipeline that can ingest, process, index, and serve insights from long-form video. A modern solution built on deep learning principles offers capabilities that were previously unattainable. These systems are not just about watching; they are about understanding and predicting. By focusing on key functional areas, organizations can construct a powerful engine for video intelligence that drives tangible business outcomes, turning passive data streams into active assets for decision-making.
Automated Event Detection and Summarization
A primary capability of a long-context system is its ability to automatically detect complex, multi-step events without pre-programmed rules. By training on hours of footage, a model learns the signature of a specific process, like a complete customer transaction or a multi-stage manufacturing assembly. It can then identify these events in new footage, timestamp them, and classify them. Furthermore, the system can generate concise summaries of long videos, highlighting only the most relevant events. For example, it could condense 8 hours of security footage into a 2-minute summary showing every person and vehicle that entered a specific zone, saving immense time in manual review.
Semantic Search Across Entire Archives
This is arguably the most transformative capability. Traditional systems rely on searching metadata that has been manually tagged. A modern pipeline enables true semantic search, allowing users to query their video archive using natural language or example images. This is powered by the vector embeddings stored in a database like VideoDB. An engineer can search for "show me all clips where a machine is making an unusual vibrating sound" or "find instances of near-miss safety incidents at the loading dock." The system retrieves relevant segments by comparing the semantic meaning of the query to the video content embeddings, rather than matching keywords. This unlocks an unprecedented level of accessibility to the information locked within video.
Anomaly and Pattern Recognition
Long-context analysis is exceptionally powerful for anomaly detection. The system can ingest weeks or months of video to build a deep model of what constitutes 'normal' operation. This could be the typical flow of traffic in a city, the standard movements of a robotic arm, or the usual customer behavior in a store. Once this baseline is established, the AI can automatically flag any significant deviations in real-time. This could be a sudden crowd formation, a subtle stutter in a machine's motion that precedes a breakdown, or a shopper lingering in an unusual area. This capability shifts the paradigm from reactive investigation to proactive intervention, driven by the 29.2% CAGR in AI adoption for video analysis.
Long-Context Analysis in Practice
Theoretical capabilities become truly valuable when applied to solve real-world business problems. The power of long-context video analysis is being demonstrated across a variety of industries, transforming operational efficiency, safety, and customer experience. These applications move far beyond simple security monitoring, turning video data into a core driver of strategic decision-making.
Manufacturing: Proactive Quality Control
In a high-volume automotive manufacturing plant, subtle inconsistencies in robotic welding arms can lead to microscopic defects that are only caught much later in quality assurance, causing costly rework. A long-context AI system was implemented to continuously monitor hundreds of hours of video from the welding stations. The model learned the precise, acceptable motion paths, speeds, and spark patterns of a perfect weld. It now automatically flags any robotic arm that exhibits minute, yet persistent, deviations from this learned baseline, often hours before a measurable defect occurs. This proactive alerting has reduced the defect rate from this specific process by 15% and saved over 200 hours per month in manual inspection and rework.
Retail: Optimizing Customer Journey and Store Layout
A large format retail chain wanted to understand how customers really used their stores, beyond simple sales data. They deployed a video analytics platform to analyze long-term customer flow patterns across several locations over a three-month period. The system tracked anonymized customer paths, dwell times in different aisles, and common patterns of interaction with displays. The analysis revealed a major bottleneck near the entrance that was causing 30% of customers to bypass a high-margin promotional area. Based on these insights, the store redesigned the layout, leading to a 12% increase in sales from that section and a measurable improvement in overall customer flow.
Media & Entertainment: Automating Content Discovery
A major streaming service with a library of over 50,000 hours of content struggled to help users discover relevant material. Their recommendation engine relied on user-provided tags and viewing history, which often missed the nuanced content of the videos themselves. They integrated a long-context video understanding system to scan their entire archive, generating rich metadata about scenes, emotional tone, recurring characters, and even specific objects or brands. This allowed them to build a powerful semantic search engine. Users can now search for "movies with tense interrogation scenes" or "documentaries featuring Mount Everest," and the system provides highly relevant results, increasing user engagement by 25% and reducing subscription churn.
Industry Voices on Video's Future
Dr. Fei-Fei Li, Professor of Computer Science at Stanford University, emphasized in MIT Technology Review that understanding long-term dependencies in video is crucial for building truly intelligent systems that can comprehend causality and narrative, moving beyond simple pattern recognition. (2017)
Andrew Ng, Founder of Landing AI, mentioned in Forbes that video analytics is transforming industries by providing actionable insights from visual data, enabling businesses to optimize processes, improve quality control, and enhance safety in ways that were previously impossible. (2022)
Your Roadmap to Video Intelligence
Adopting long-context video analysis is a strategic initiative that can yield significant returns. However, a successful implementation requires a structured approach. Following a clear roadmap ensures that the technology is aligned with business objectives and that the foundational elements are in place for a scalable, effective solution. Here is a five-step plan to guide your organization's journey from raw footage to actionable insights.
Define a Specific Business Objective
Before writing a single line of code, identify the precise problem you want to solve. Is it reducing defects on a production line, optimizing retail store layout, or improving security response times? A clear objective will guide your data collection strategy, model selection, and the definition of success metrics. Start with a single, high-impact use case to demonstrate value quickly before expanding.
Establish a Data Ingestion and Preparation Pipeline
Your models are only as good as the data they are trained on. You need a robust pipeline to collect, store, and pre-process video from various sources. This involves standardizing formats, handling different resolutions and frame rates, and ensuring data is properly labeled for initial model training. Consider the network and storage infrastructure required to handle the massive data volumes involved.
Select and Fine-Tune Appropriate Deep Learning Models
Start with pre-trained models for common tasks like object detection and action recognition, and then fine-tune them on your specific data. For understanding temporal context, explore architectures like LSTMs or Transformers. The key is to choose models that balance performance with computational efficiency for your specific use case. This stage requires expertise in machine learning and a willingness to experiment.
Implement a Scalable Indexing and Search System
Once your models are extracting features and events, you need an efficient way to store and query them. This is where a specialized vector database is essential. A solution like VideoDB is purpose-built to handle the scale and query types required for video, enabling real-time semantic search across petabytes of data. Trying to build this capability on a traditional database will create significant performance bottlenecks.
Integrate, Deploy, and Iterate
The final step is to integrate the insights from your video analysis pipeline into existing business applications and workflows. This could be a dashboard for plant managers, an alerting system for security teams, or an input for a recommendation engine. Deploy the system, monitor its performance against your initial objectives, and use the feedback to continuously retrain and improve your models.
Common Questions About Long-Context Video Analysis
Q: What is the main difference between traditional video analytics and long-context AI analysis?
A: Traditional analytics typically focus on simple, rule-based alerts for individual frames, like detecting motion in a predefined area. Long-context AI analysis uses deep learning to understand the sequence of events over time, enabling it to identify complex behaviors, patterns, and anomalies that have no simple rules. It's the difference between seeing a person and understanding their entire journey through a building.
Q: What kind of hardware is required to run these advanced AI models?
A: Processing long-form video is computationally intensive and almost always requires GPUs (Graphics Processing Units) for efficient model training and inference. While on-premise servers with high-end GPUs are an option, many organizations leverage cloud-based solutions from providers like AWS, Google Cloud, or Azure. This provides the scalability to handle fluctuating workloads and access to the latest hardware without a large capital investment.
Q: How does this technology handle real-time video streams versus archived footage?
A: The architecture can be adapted for both. For real-time analysis, the pipeline processes video chunk by chunk as it is ingested, running inference to detect events and anomalies as they happen. For archived footage, the same pipeline can be run in a batch processing mode to analyze and index large volumes of historical data, making the entire archive searchable and useful for trend analysis.
Q: Is it really possible to search for abstract concepts like "a confused customer"?
A: Yes, this is a key benefit of semantic search powered by vector embeddings. By training a model on examples of what constitutes a "confused customer" (e.g., pacing, repeatedly looking at a map, circling the same area), the system learns the vector representation of that concept. When you search for that phrase, the system looks for video segments whose embeddings are semantically similar in the high-dimensional space, allowing for surprisingly nuanced and abstract queries.
Q: What are the biggest challenges when implementing a long-context video analysis system?
A: The primary challenges are typically data management, computational cost, and model accuracy. Managing and preparing the massive volumes of video data required for training can be complex. The computational resources (specifically GPUs) can be expensive, requiring careful optimization. Finally, ensuring the model is accurate and avoids bias requires rigorous testing, validation, and continuous retraining with diverse and representative data.
Key Takeaways
Approximately 80% of video data is unanalyzed, representing a massive opportunity for AI-driven insights.
Long-context video analysis shifts from single-frame detection to understanding temporal narratives and complex events over time.
A modern architecture relies on computer vision for perception, deep learning for temporal modeling, and vector databases like VideoDB for scalable semantic search.
Key capabilities include automated event summarization, natural language search, and proactive anomaly detection.
Real-world applications in manufacturing, retail, and media are already driving significant ROI by improving efficiency, safety, and customer experience.









