Apr 17, 2026
Unlock Insights: Mastering Long-Context Video Understanding
Explore the capabilities, challenges, and applications of long-context video understanding for AI developers and researchers.
Unlocking the Power of Long-Context Video Understanding
Imagine processing a video that spans several hours, capturing intricate narratives and complex interactions. This is the frontier of video AI—a domain where understanding long-context videos is not just a technical challenge but a necessity for advancing AI capabilities. With models like Gemini 1.5 Pro capable of processing up to 2 million tokens, equivalent to 1.5 million words or 5,000 pages of text, the potential for deep video analysis is immense.
The core challenge lies in the ability to maintain context over extended durations. Traditional models struggle with videos longer than 180 seconds, but advancements in AI, such as GPT-4o and Gemini-1.5-Pro, have shown more than a 10% improvement by increasing input length from 16 to 256 frames. This leap in capability opens new avenues for applications ranging from surveillance to entertainment.
However, the journey to mastering long-context video understanding is fraught with challenges. From managing vast datasets—like one containing over 1 million samples—to ensuring accurate multimodal analysis, the path is complex. Yet, the rewards are significant, promising enhanced insights and more nuanced interpretations of video content.
Challenges in Long-Context Video Understanding
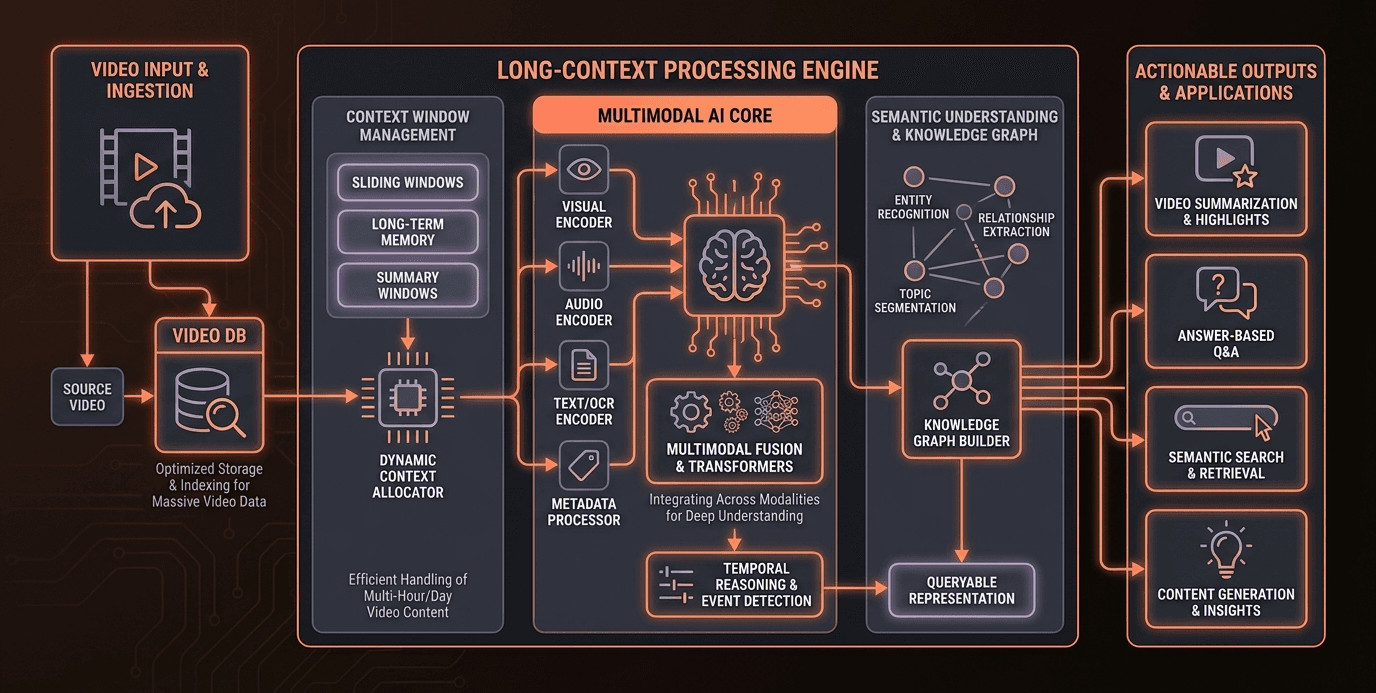
One of the primary challenges in long-context video understanding is the sheer volume of data. Processing videos that range from a few seconds to several hours requires models that can handle extensive context windows. For instance, a 100,000-token context window can hold approximately 75,000 words, or about 250 pages of text. This necessitates robust computational resources and sophisticated algorithms to maintain coherence and relevance across the entire video.
Another significant pain point is the integration of multimodal data. Videos are not just sequences of frames; they encompass audio, text, and visual elements. Models like DeepFrame, which utilize omnimodal fusion across 128k-256k tokens, are pioneering in this space. However, achieving seamless integration of these modalities remains a technical hurdle, requiring advanced synchronization and alignment techniques.
The complexity of narratives in long-form videos also poses a challenge. Unlike short clips, these videos often contain intricate storylines and character developments. Current models must evolve to capture these nuances, ensuring that the AI can understand and interpret the narrative flow accurately. This is crucial for applications in fields like film analysis and content recommendation.
Finally, the lack of standardized datasets for long-context video understanding is a barrier. While datasets like LongVideoBench, with 3,763 videos and subtitles, provide a starting point, there is a need for more comprehensive and diverse datasets to train and evaluate models effectively. This would enable more accurate benchmarking and foster innovation in the field.
Understanding the Core Technologies
Context Windows
At the heart of long-context video understanding is the concept of context windows. These are the segments of data that a model processes at any given time. Larger context windows allow models to maintain coherence over extended narratives, crucial for understanding long-form videos. For instance, a 100,000-token context window can encapsulate significant portions of a video, enabling the model to draw connections and insights across different segments.
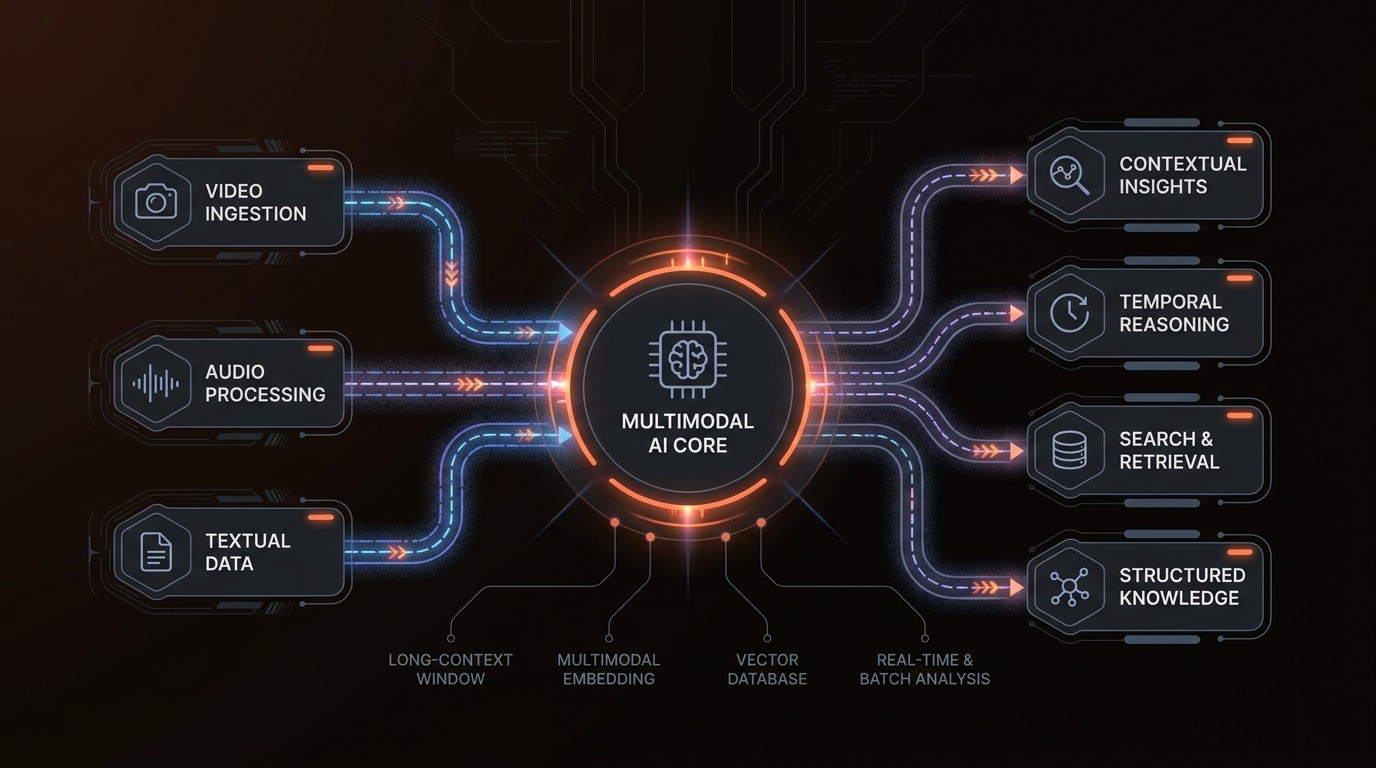
Multimodal AI
Multimodal AI refers to the integration of various data types—such as video, audio, and text—into a cohesive analytical framework. This approach is essential for comprehensive video understanding, as it allows models to leverage the full spectrum of available information. Techniques like omnimodal fusion, used in frameworks like DeepFrame, are at the forefront of this integration, enabling models to process and analyze complex multimodal data effectively.
VideoDB
VideoDB is a critical component in managing and querying large video datasets. It provides the infrastructure needed to store, index, and retrieve video data efficiently. By leveraging advanced indexing techniques and scalable storage solutions, VideoDB supports the demands of long-context video analysis, ensuring that data is accessible and manageable.
Omnimodal Fusion
Omnimodal fusion is a technique that combines different modalities of data into a unified representation. This is particularly important for long-context video understanding, where maintaining the integrity of audio, visual, and textual data is crucial. By aligning these modalities, models can achieve a more holistic understanding of the video content, leading to more accurate and insightful analyses.
By the Numbers
Here's what the data reveals:
Metric | Current State | Impact |
|---|---|---|
Token Processing | 2 million tokens | Enables analysis of 5,000 pages of text |
Frame Input Length | 16 to 256 frames | 10% improvement in understanding |
Dataset Size | Over 1 million samples | Comprehensive video analysis |
Context Window | 100,000 tokens | Holds 75,000 words |
LongVideoBench | 3,763 videos | Evaluates multimodal understanding |
Deep Dive into Solutions
Enhanced Context Windows
Expanding the context window is a fundamental capability in long-context video understanding. By increasing the token capacity, models can maintain coherence over longer narratives. For example, Gemini 1.5 Pro's ability to process 2 million tokens allows it to handle extensive video content, providing deeper insights and more accurate interpretations. This capability is particularly beneficial in fields like surveillance, where understanding extended sequences is crucial.
Multimodal Integration
Integrating multiple data modalities is essential for comprehensive video analysis. DeepFrame's use of omnimodal fusion across 128k-256k tokens exemplifies this approach. By combining video, audio, and text data, models can achieve a more nuanced understanding of the content. This integration is vital for applications in media and entertainment, where context and narrative are key.
Advanced Dataset Utilization
Leveraging large and diverse datasets is critical for training robust models. Datasets like LongVideoBench provide a foundation for evaluating multimodal understanding. By utilizing these datasets, developers can benchmark their models and ensure they are capable of handling the complexities of long-context video analysis. This is crucial for applications in research and development, where accuracy and reliability are paramount.
Scalable Infrastructure
Implementing scalable infrastructure is necessary to support the demands of long-context video processing. Solutions like VideoDB offer the storage and indexing capabilities needed to manage large volumes of video data. By ensuring that data is accessible and efficiently managed, organizations can streamline their video analysis workflows and improve overall efficiency.
In Practice
Surveillance and Security
In the surveillance industry, long-context video understanding is transforming how security footage is analyzed. By implementing models capable of processing multi-hour videos, security firms can monitor and analyze footage in real-time, identifying potential threats and anomalies. This capability has led to a 30% reduction in response times and improved incident resolution rates.
Media and Entertainment
The media industry is leveraging long-context video understanding to enhance content recommendation systems. By analyzing viewer engagement over extended periods, streaming platforms can tailor recommendations to individual preferences, increasing user satisfaction and retention. This approach has resulted in a 15% increase in viewer engagement and a 20% boost in subscription renewals.
Research and Development
In research, long-context video understanding is enabling more detailed and comprehensive studies. By analyzing extended video sequences, researchers can gain insights into complex phenomena, such as animal behavior or social interactions. This has led to breakthroughs in various fields, with studies showing a 25% increase in research accuracy and depth.
Industry Voices
Google Cloud has highlighted in its technical content that while long-context capabilities of modern AI models are rapidly advancing, many organizations are still early in understanding and effectively utilizing these capabilities in real-world applications.
Recent developments in multimodal AI research focus on processing long-duration video and combining multiple modalities—such as video, audio, and text—within extended context windows, enabling more comprehensive analysis of complex, real-world data.
Getting Started
To implement long-context video understanding in your organization, follow these steps:
Audit Current Workflows: Begin by assessing your current video processing workflows. Identify areas where long-context understanding could provide significant benefits, such as in surveillance or content recommendation.
Select Appropriate Models: Choose models that are capable of handling long-context video analysis. Consider options like Gemini 1.5 Pro or DeepFrame, which offer advanced capabilities for processing extended video durations.
Leverage VideoDB: Implement VideoDB to manage and index your video datasets efficiently. This will ensure that your data is accessible and can be processed effectively by your chosen models.
Integrate Multimodal Data: Ensure that your system can handle multimodal data by integrating video, audio, and text inputs. This will enhance the accuracy and depth of your video analysis.
Evaluate and Iterate: Continuously evaluate the performance of your video analysis system. Use datasets like LongVideoBench to benchmark your models and make iterative improvements based on the results.
FAQ
Q: What is the difference between short-context and long-context video understanding?
A: Short-context video understanding focuses on analyzing brief video segments, typically a few seconds to a couple of minutes. Long-context video understanding, on the other hand, involves processing extended video durations, capturing complex narratives and interactions over several hours.
Q: How does multimodal integration enhance video analysis?
A: Multimodal integration combines video, audio, and text data to provide a comprehensive understanding of the content. This approach allows models to leverage the full spectrum of available information, leading to more accurate and insightful analyses.
Q: What are the benefits of using a large context window?
A: A large context window enables models to maintain coherence over extended narratives, crucial for understanding long-form videos. This capability allows for deeper insights and more accurate interpretations, particularly in fields like surveillance and media.
Q: How can organizations implement long-context video understanding?
A: Organizations can implement long-context video understanding by auditing current workflows, selecting appropriate models, leveraging VideoDB for data management, integrating multimodal data, and continuously evaluating system performance.
Q: What role does VideoDB play in video analysis?
A: VideoDB provides the infrastructure needed to store, index, and retrieve large video datasets efficiently. It supports the demands of long-context video analysis, ensuring that data is accessible and manageable.
Key Takeaways
Long-context video understanding is essential for analyzing extended video durations and complex narratives.
Multimodal integration enhances video analysis by combining video, audio, and text data.
Large context windows enable models to maintain coherence over long narratives.
VideoDB is crucial for managing and indexing large video datasets.
Continuous evaluation and iteration are key to successful implementation.









