Apr 17, 2026
RAGFlow: Revolutionizing AI with Deep Document Understanding
Explore how RAGFlow enhances AI with deep document understanding, offering accurate, citation-backed question answering from complex data.
Transforming AI with RAGFlow's Deep Document Understanding
In the realm of artificial intelligence, the ability to process and understand complex documents is a game-changer. RAGFlow, an open-source Retrieval-Augmented Generation (RAG) engine, is at the forefront of this transformation. By integrating deep document understanding with large language models (LLMs), RAGFlow offers developers and researchers a powerful tool for accurate, citation-backed question answering. This capability is crucial in scenarios where precision and reliability are paramount, such as legal document analysis or academic research.
The core challenge in AI-driven document understanding lies in the complexity and diversity of data sources. Traditional methods often struggle with multimodal data, including images, scanned documents, structured data, and web pages. RAGFlow addresses this by supporting a wide range of data types, ensuring comprehensive analysis and retrieval. This versatility is essential for applications that require a holistic view of information, such as financial audits or medical diagnostics.
Moreover, RAGFlow significantly reduces AI hallucinations by providing grounded citations and visualizing text chunking. This feature not only enhances the credibility of AI-generated responses but also aids users in tracing the origin of information. In an era where misinformation can have dire consequences, such transparency is invaluable. As we delve deeper into the capabilities of RAGFlow, it becomes evident that this technology is not just an incremental improvement but a revolutionary step forward in AI document understanding.
Challenges in Document Understanding
The journey to achieving deep document understanding in AI is fraught with challenges. One significant pain point is the sheer volume of data that needs to be processed. With datasets often exceeding 100TB, traditional systems struggle to scale effectively. This limitation hampers the ability to retrieve relevant information quickly, leading to inefficiencies in data-driven decision-making processes.
Another challenge is the diversity of data formats. Documents can range from structured spreadsheets to unstructured text and images. This heterogeneity requires sophisticated parsing techniques to ensure accurate interpretation. Without such capabilities, AI systems risk misinterpreting data, leading to flawed insights and potentially costly errors in fields like finance or healthcare.
The issue of AI hallucinations further complicates document understanding. When AI models generate responses not grounded in the source data, it undermines trust in the technology. This is particularly problematic in legal or academic settings, where accuracy and verifiability are non-negotiable. RAGFlow addresses this by offering grounded citations, ensuring that every piece of information can be traced back to its origin.
Finally, optimizing retrieval strategies for deep-research scenarios is a critical challenge. High recall accuracy is essential for applications like scientific research, where missing a single relevant document can skew results. RAGFlow's advanced retrieval algorithms enhance recall accuracy, ensuring comprehensive data coverage and reliable outcomes.
Understanding RAGFlow's Core Technologies
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is a technique that combines retrieval-based methods with generative models to enhance the accuracy of AI responses. By retrieving relevant documents from a vast corpus, RAGFlow ensures that the generated answers are grounded in factual data. This approach mitigates the risk of AI hallucinations and enhances the reliability of AI-driven insights.
Large Language Models (LLMs)
Large Language Models (LLMs) are at the heart of RAGFlow's capabilities. These models are trained on extensive datasets, enabling them to understand and generate human-like text. By integrating LLMs with deep document understanding, RAGFlow can process complex documents and provide nuanced, context-aware responses. This capability is crucial for applications requiring detailed analysis, such as legal document review or academic research.
Deep Document Understanding
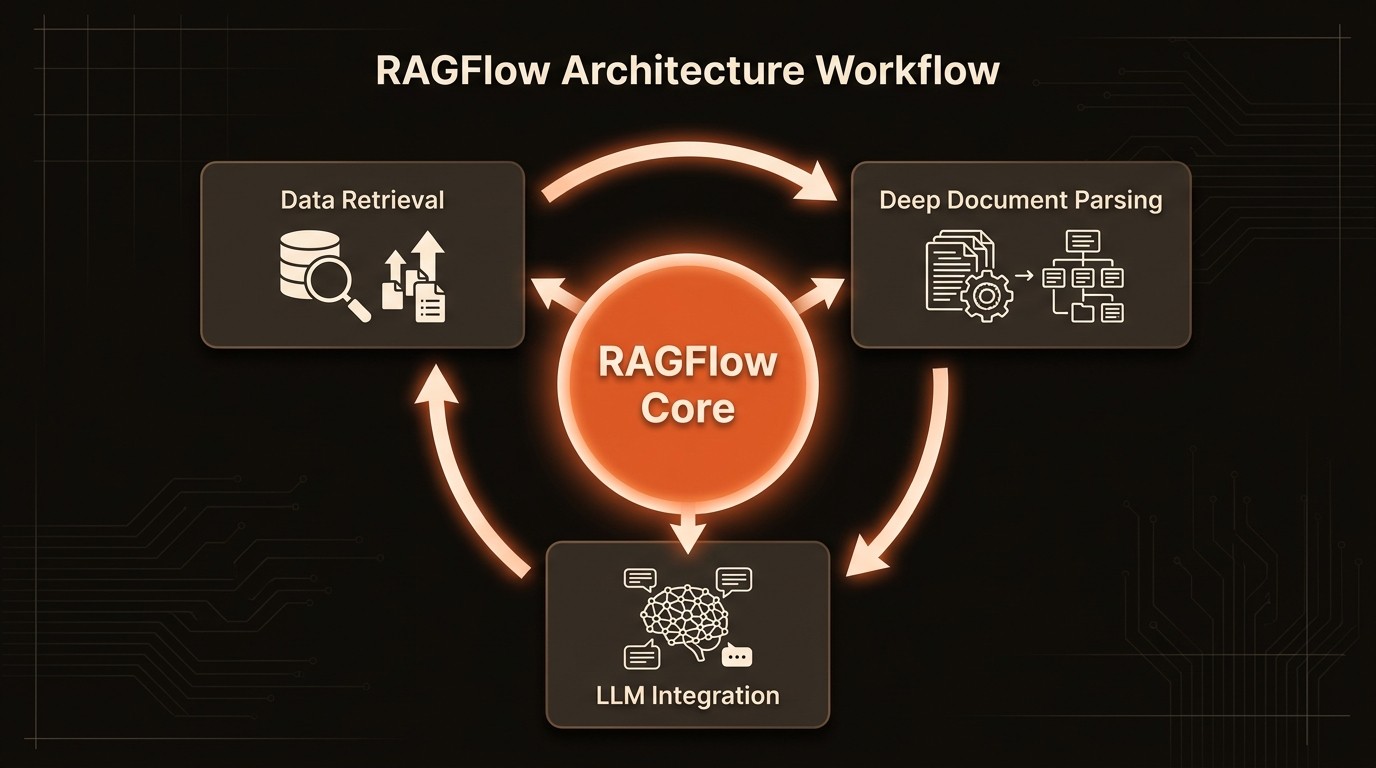
Deep Document Understanding involves the use of advanced algorithms to parse and interpret complex document structures. RAGFlow employs techniques like DeepDoc to detect document layouts and parse intricate structures, ensuring accurate data extraction. This capability is essential for handling diverse data formats, from scanned images to structured spreadsheets, and is a key differentiator in RAGFlow's technology stack.
Multimodal Data Support
RAGFlow's ability to support multimodal data is a significant advantage. By accommodating various data types, including images, text, and structured data, RAGFlow provides a comprehensive analysis of information. This versatility is crucial for applications that require a holistic view of data, such as financial audits or medical diagnostics, where different data formats must be integrated seamlessly.
By the Numbers
Here's what the data reveals:
Metric | Current State | Impact |
|---|---|---|
Data Volume | 100TB+ | Scalable backend components |
Processing Time Reduction | 50% | Faster task completion |
AI Hallucinations | Reduced | Grounded citations |
Multimodal Data Support | Comprehensive | Enhanced data analysis |
Recall Accuracy | Optimized | Improved research outcomes |
Unpacking RAGFlow's Capabilities
Deep Document Parsing
RAGFlow's deep document parsing capabilities are powered by advanced algorithms that detect and interpret complex document structures. This feature is particularly beneficial in industries like finance, where documents often contain intricate layouts and embedded data. By accurately parsing these documents, RAGFlow ensures that no critical information is overlooked, enhancing decision-making processes.
Multimodal Data Integration
The ability to integrate multimodal data is a standout feature of RAGFlow. By supporting various data types, including images and structured data, RAGFlow provides a comprehensive analysis of information. This capability is crucial for applications like medical diagnostics, where different data formats must be analyzed together to provide accurate insights.
Optimized Retrieval Strategies
RAGFlow's optimized retrieval strategies enhance recall accuracy, making it ideal for deep-research scenarios. By employing advanced algorithms, RAGFlow ensures that all relevant documents are retrieved, providing a comprehensive data set for analysis. This feature is particularly valuable in scientific research, where missing a single document can skew results.
Grounded Citations and Visualization
One of RAGFlow's most significant advantages is its ability to provide grounded citations and visualize text chunking. This feature enhances the credibility of AI-generated responses by allowing users to trace information back to its source. In fields like law or academia, where accuracy and verifiability are paramount, this capability is invaluable.
In Practice
Legal Document Analysis
In the legal industry, the ability to analyze complex documents quickly and accurately is crucial. RAGFlow's deep document understanding capabilities allow legal professionals to parse intricate contracts and legal texts efficiently. By providing grounded citations, RAGFlow ensures that all interpretations are verifiable, reducing the risk of legal disputes and enhancing trust in AI-driven insights.
Academic Research
For researchers, access to comprehensive and accurate data is essential. RAGFlow's optimized retrieval strategies ensure that all relevant documents are retrieved, providing a robust data set for analysis. This capability enhances the quality of research outcomes, enabling researchers to draw more reliable conclusions and advance their fields of study.
Financial Audits
In the financial sector, audits require the integration of various data formats, from spreadsheets to scanned documents. RAGFlow's multimodal data support allows auditors to analyze these diverse data types seamlessly, ensuring comprehensive audits and reducing the risk of oversight. This capability enhances the accuracy and efficiency of financial audits, leading to more reliable financial reporting.
Industry Voices
Yongteng Lei, Software Engineer at InfiniFlow, noted in Vector Search Conference 2025 that RAGFlow tackles challenges by ensuring the quality of pre-processed data using DeepDoc, which detects document layouts and parses intricate structures within documents. (2025)
Dimitri Bellini, on Quadrata channel, highlights RAGFlow's focus on accurate document analysis, integration of advanced techniques, ease of use via Docker and Ollama, and inclusion of collaboration and API features. (2025)
Getting Started with RAGFlow
Implementing RAGFlow in your organization involves several key steps to ensure a smooth transition and maximize its benefits.
Assess Current Document Processing Workflows: Begin by evaluating your existing document processing workflows. Identify areas where RAGFlow's capabilities can enhance efficiency and accuracy. This assessment will help you prioritize implementation efforts and allocate resources effectively.
Set Up RAGFlow Environment: Utilize Docker and Ollama to set up the RAGFlow environment. These tools simplify the deployment process, allowing you to get started quickly. Ensure that your infrastructure can handle the data volume and processing requirements of RAGFlow.
Integrate Multimodal Data Sources: RAGFlow's strength lies in its ability to handle diverse data types. Integrate your existing data sources, including images, text, and structured data, to leverage RAGFlow's full potential. This integration will provide a comprehensive view of your data landscape.
Optimize Retrieval Strategies: Customize RAGFlow's retrieval strategies to align with your specific needs. This optimization will enhance recall accuracy and ensure that all relevant documents are retrieved for analysis. Tailor these strategies to suit your industry and application requirements.
Monitor and Evaluate Performance: After implementation, continuously monitor RAGFlow's performance. Evaluate its impact on processing times, accuracy, and overall efficiency. Use these insights to make data-driven adjustments and further optimize your workflows.
FAQ
Q: What is RAGFlow's primary advantage over traditional document processing methods?
A: RAGFlow's primary advantage is its ability to integrate deep document understanding with LLMs, providing accurate, citation-backed question answering. This capability reduces AI hallucinations and enhances the reliability of AI-driven insights.
Q: How does RAGFlow handle multimodal data?
A: RAGFlow supports various data types, including images, scanned documents, structured data, and web pages. This versatility allows for comprehensive data analysis, making it suitable for applications that require a holistic view of information.
Q: What industries can benefit most from RAGFlow?
A: Industries such as legal, academic research, and finance can benefit significantly from RAGFlow. Its capabilities in deep document understanding and multimodal data integration enhance accuracy and efficiency in these fields.
Q: How does RAGFlow reduce AI hallucinations?
A: RAGFlow reduces AI hallucinations by providing grounded citations and visualizing text chunking. This feature ensures that AI-generated responses are verifiable and traceable to their source data.
Q: What are the technical requirements for implementing RAGFlow?
A: Implementing RAGFlow requires infrastructure capable of handling large datasets and processing demands. Tools like Docker and Ollama facilitate the setup process, ensuring a smooth deployment.
Key Takeaways
RAGFlow integrates deep document understanding with LLMs for accurate AI insights.
Supports multimodal data, enhancing comprehensive data analysis.
Reduces AI hallucinations with grounded citations and text visualization.
Optimizes retrieval strategies for deep-research scenarios.
Implementation requires infrastructure capable of handling 100TB+ datasets.









