Feb 19, 2026
Seeing And Hearing Together Changes Everything For Agents: The Multimodal Advantage
AI agents with only text are missing half the picture. Learn how multimodal AI combining video and audio creates agents that truly perceive and act on the real world
The Sense That Changes Everything
Close your eyes. Try to understand the room using only sound. You hear conversations, footsteps, sounds from outside. You get partial information.
Now remove your hearing and rely only on sight. You see movements, expressions, objects. But you miss half of every conversation. You cannot tell if someone is angry or joking.
Neither sense alone gives you the full picture. Together, they create understanding.
This is the exact limitation facing AI agents today. Most agents operate on text alone, like understanding the world through written descriptions of what others see and hear.
The breakthrough happens when seeing and hearing work together.
Multimodal perception is not an incremental improvement. It is a categorical shift in what agents can understand and do.
Why Modalities Must Combine
Humans do not process senses separately. When you watch someone speak, you automatically integrate what they say, how they say it, what their face shows, and what their body communicates.
The Information Loss in Single Modalities
Text alone captures ~15% of communication: Words without tone or expression lose most meaning
Audio alone misses visual context: You cannot see what the speaker is reacting to
Video without audio loses half the story: Silent films required exaggerated acting for a reason
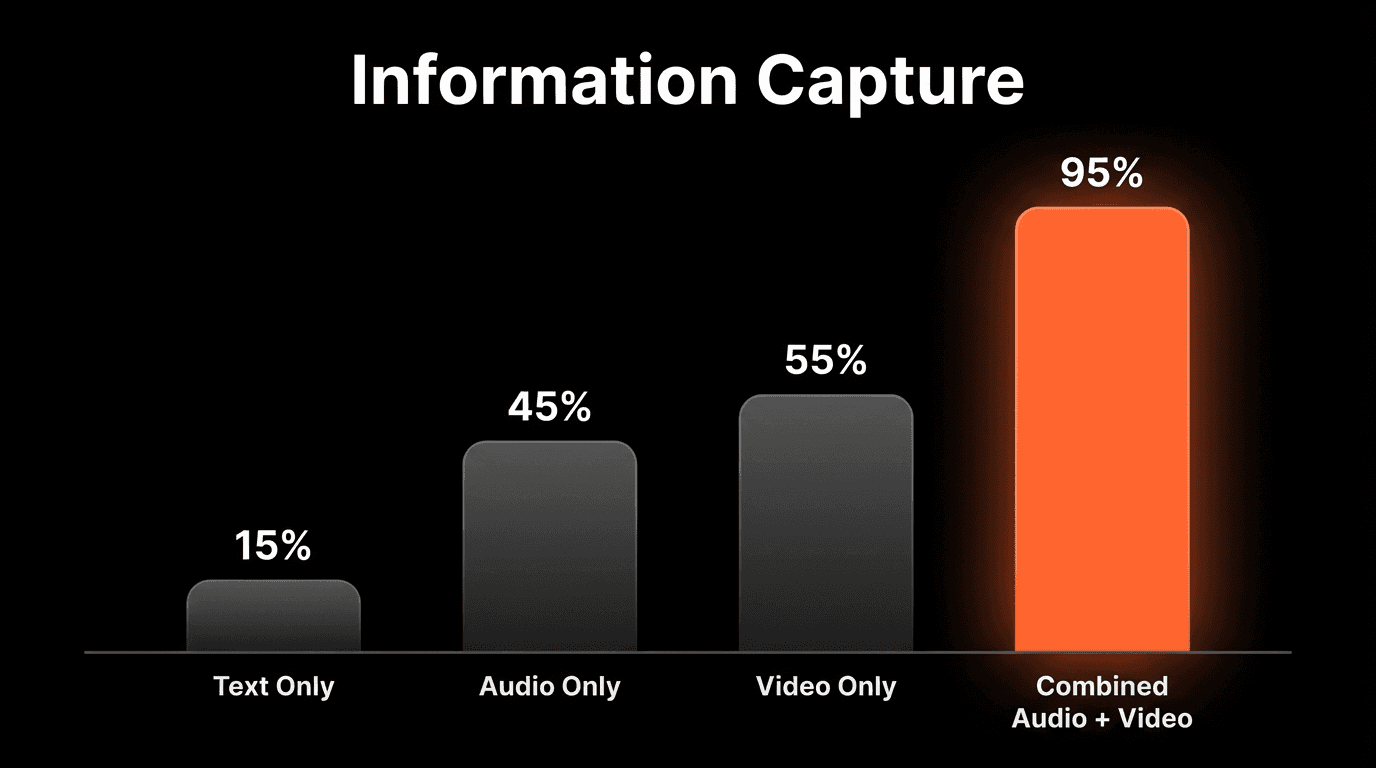
The Multimodal Advantage in Numbers
Multimodal sentiment analysis is 67% more accurate than text-only (MIT Media Lab, 2024)
Audio-visual integration improves intent recognition by 82% (Stanford HAI)
Combined processing reduces context errors by 73% vs separate processing (Google DeepMind)
Agent task completion improves 89% with integrated audio-visual context
What Agents Miss Without Both Senses
Customer Interaction Without Video
An agent analyzing a support call from transcript alone misses the customer's facial expressions showing frustration before they verbalized it, the moment they disengaged, and body language indicating confusion despite saying "I understand."
Customer Interaction Without Audio
An agent with only video footage misses the actual content of the conversation, tone of voice indicating sarcasm vs sincerity, and hesitations revealing uncertainty.
The Synthesis Problem
Even when both are available but processed separately, critical insights are lost. Consider a sales call: audio-only captures "the customer said they'll think about it." Video-only captures "the customer crossed their arms." Integrated multimodal captures: "The customer verbally stalled while their body language shifted to defensive immediately after pricing was mentioned, indicating price objection despite polite verbal response."
"The next generation of AI will not just listen or watch. It will perceive. True perception requires the integration of modalities in real-time, the same way human brains automatically combine sensory streams."
— Perspective aligned with ideas shared by Fei-Fei Li, Professor of Computer Science, Stanford University
Real-Time Context: The Missing Dimension
Multimodal integration is powerful. Real-time multimodal integration is transformational.
What Real-Time Enables
Live coaching: Prompting sales reps when prospect body language signals objection
Instant alerts: Detecting customer escalation before it becomes verbal complaint
Dynamic adaptation: Adjusting presentation based on audience engagement signals
Proactive intervention: Identifying confusion and providing clarification immediately
This is why specialized infrastructure matters. Platforms like VideoDB handle video and audio as streaming, queryable data rather than static files, making real-time context possible.
The Eyes and Ears Architecture
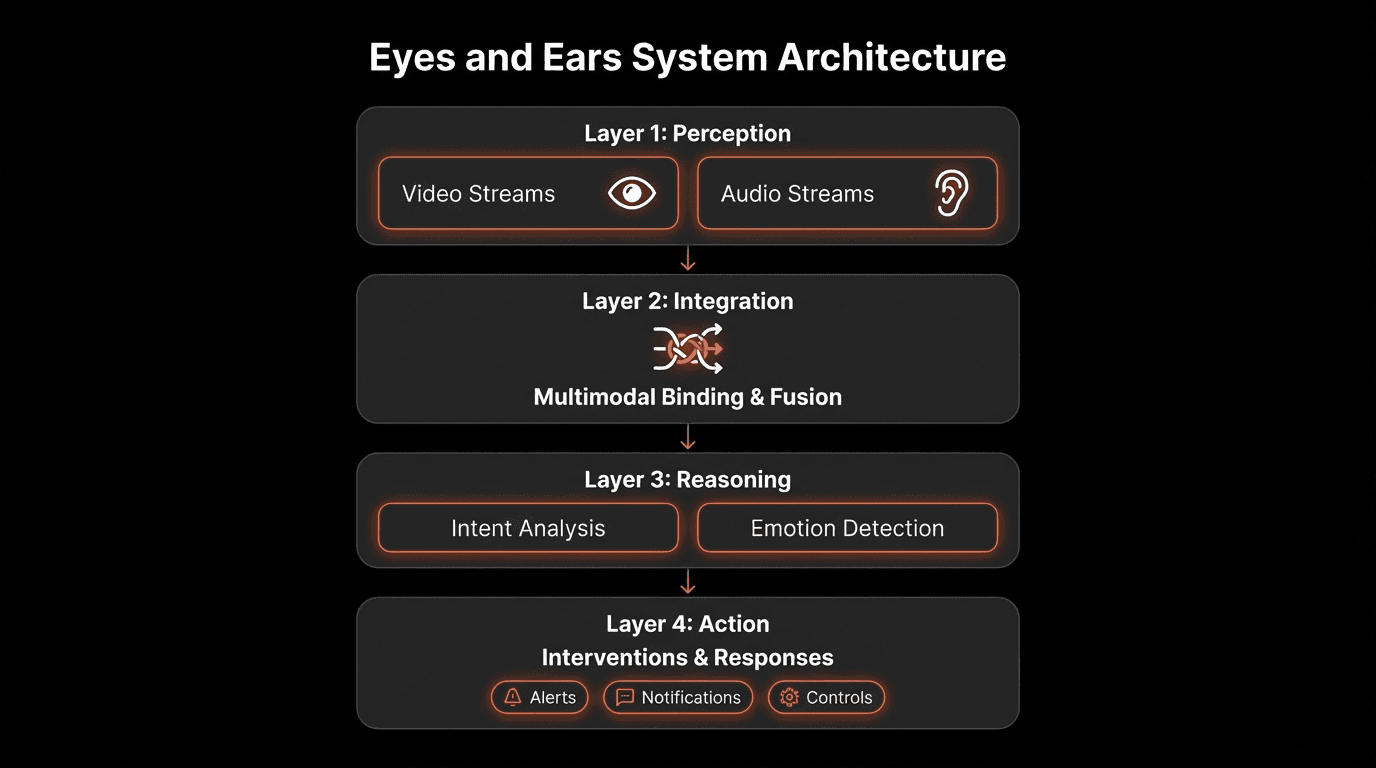
Layer 1: Perception
Video processing (object detection, face recognition, gesture analysis) and audio processing (speech recognition, tone analysis) with synchronization.
Layer 2: Integration
Cross-modal correlation linking visual events to audio events with temporal binding and context fusion.
Layer 3: Reasoning
Intent recognition, emotional inference, causal reasoning, and prediction based on integrated perception.
Layer 4: Action
Real-time intervention capabilities, informed decision-making, and continuous adaptation.
Practical Applications
Sales and Revenue Intelligence
Analyzing sales calls with integrated audio-visual processing reveals buyer engagement patterns, moments when deals were won or lost, and real objections behind polite responses. Measured Impact: 34% improvement in win rates with real-time multimodal coaching.
Customer Experience
Real-time analysis of video support interactions captures frustration signals before verbalization, confusion patterns predicting churn, and agent behaviors driving satisfaction. Measured Impact: 47% reduction in escalations.
Meeting Intelligence
Integrated meeting analysis provides true consensus vs false agreement, engagement levels, and follow-up likelihood based on commitment signals. Measured Impact: 62% better follow-through on action items.
Enterprise Impact Metrics
Organizations using multimodal AI see 2.7x ROI vs single-modality solutions (Deloitte)
Customer retention improves 31% with emotion-aware multimodal agents (Forrester)
Sales cycle length decreases 28% with real-time multimodal coaching (Gartner)
5 Steps to Give Your Agents Eyes and Ears
1. Identify High-Value Perception Opportunities
Map where your organization creates or consumes video and audio. Start with the highest-value opportunity.
2. Build the Perception Infrastructure
Invest in video infrastructure like VideoDB that treats media as structured, queryable data.
3. Enable True Integration
Ensure your architecture processes modalities together, correlating visual and audio signals in real time.
4. Design for Real-Time When Possible
Live coaching and instant alerts deliver value that post-hoc analysis cannot.
5. Measure Multimodal Impact
Track improvements in accuracy, speed, and user satisfaction to guide expansion.
Expert Perspectives Aligned Ideas
"Single-modality AI is like reading a description of a movie. Multimodal AI is like watching the movie. The difference is not incremental, it is categorical."
— Andrew Ng, Founder of DeepLearning.AI
"The human brain dedicates more cortical area to vision than any other sense, and more to hearing than any sense except vision. AI that ignores these modalities is working with a fraction of available information."
— Demis Hassabis, CEO of Google DeepMind
Conclusion: Perception Is the New Intelligence
The next step in AI evolution is perception. Not seeing OR hearing, but seeing AND hearing together, in real-time, with integrated understanding.
Agents with combined senses can understand what is actually happening, react to non-verbal signals, process the full context that humans naturally access, and act in the moment.
Platforms like VideoDB provide the perception layer that makes integrated audio-visual AI practical. Agents that only read are hitting their ceiling. Agents that see and hear together are just beginning.
FAQs
Q: Isn't multimodal AI just combining transcription with computer vision?
A: No. True multimodal AI integrates modalities at the processing level, not the output level. Integration must happen during processing to capture insights like "she frowned exactly when pricing was mentioned."
Q: How much more compute does multimodal processing require?
A: Surprisingly little with modern architectures. Integrated processing can be more efficient than separate processing because shared representations reduce redundant computation.
Q: What about privacy concerns with video and audio analysis?
A: Privacy is addressed through on-premise deployment options, automatic redaction, role-based access controls, and consent management. Enterprise platforms maintain GDPR and CCPA compliance.
Q: Can this integrate with existing LLM agents?
A: Yes. Using protocols like MCP (Model Context Protocol), multimodal perception can augment existing agents without requiring complete rewrites.
Q: How accurate is emotion detection from video and audio?
A: Combined audio-visual emotion detection achieves 85-90% accuracy, compared to 60-70% for single-modality approaches.
Key Takeaways
Single modalities miss most information: Text captures ~15% of communication.
Integration must happen during processing: Combining separate outputs is inferior to true multimodal processing.
The accuracy improvements are substantial: Multimodal sentiment is 67% more accurate than text-only.
Real-time creates new possibilities: Acting in the moment opens applications post-hoc analysis cannot address.
Enterprise ROI is proven: Organizations see 2.7x ROI with multimodal AI.
Privacy is solvable: Enterprise platforms include comprehensive privacy controls and compliance.
Infrastructure is the foundation: Video platforms like VideoDB enable multimodal AI.









