Apr 17, 2026
Supercharge Video AI: A Deep Dive into Retrieval Augmented Generation
Explore how Retrieval Augmented Generation (RAG) enhances video AI by combining external knowledge with LLMs. Learn the benefits, challenges, and applications of Video RAG.
Beyond the Pixels: Why Context is King in Video AI
Imagine a global news organization with petabytes of archived video footage. A producer is tasked with creating a segment on the evolution of sustainable energy policy over the last two years. They need to find every clip where a world leader mentions "carbon neutrality" while standing next to a solar panel. A traditional keyword search on video transcripts might find the term, but it would miss the crucial visual context. This is the fundamental challenge of modern video analysis: content is more than just words or images alone; it's a complex interplay of multimodal data where context is everything. Standard Large Language Models (LLMs), despite their impressive capabilities, are often blind to this reality, operating on a static, pre-trained knowledge base that lacks access to your specific, proprietary, or recently created video libraries.
This knowledge gap leads to significant limitations. An LLM can't tell you what happened in a live stream from five minutes ago, nor can it analyze the nuanced visual cues in a corporate training video uploaded yesterday. It operates in a vacuum, disconnected from the dynamic, ever-growing world of video content. The result is a frustrating cycle of inaccurate summaries, missed insights, and an inability to verify the AI's conclusions. To bridge this gap, we need a mechanism that can feed real-time, relevant, and verifiable context directly to the model at the moment of inquiry. This is precisely the problem that Retrieval Augmented Generation (RAG) is designed to solve, particularly in the complex domain of video.
Video RAG is an architectural approach that transforms LLMs from isolated knowledge repositories into dynamic, context-aware reasoning engines. Instead of relying solely on its training data, a RAG system first retrieves pertinent information-in this case, specific video segments, audio clips, and metadata-from an external knowledge base. This retrieved data is then provided to the LLM as a rich, contextual prompt, allowing it to generate answers that are not only accurate and relevant but also grounded in the actual source material. It’s the difference between asking a historian about a battle from memory versus giving them the field reports, maps, and soldier diaries before they answer. The quality and depth of the response are fundamentally transformed.
The Four Horsemen of Video Content Analysis
The promise of AI-driven video analysis is immense, but developers and data scientists often hit a wall defined by four persistent challenges. These issues don't just slow down development; they erode trust in AI systems and limit the potential return on investment. The first and most notorious of these is the hallucination problem. According to research from Databricks, RAG can significantly reduce hallucinations in LLMs. Without a grounding mechanism, models asked to summarize or analyze a video they haven't been explicitly trained on will often invent facts, characters, or events. For a media company trying to generate accurate summaries or a legal team performing e-discovery on video evidence, such fabrications are not just unhelpful-they are a critical liability.
Second is the staleness barrier. An LLM's knowledge is frozen at the point its training concludes. This makes it fundamentally incapable of analyzing current events, live-streamed content, or newly uploaded proprietary videos. A security firm can't use a standard LLM to ask, "Show me all vehicles that entered the facility through the north gate in the last hour." The model has no access to that real-time data stream. This forces organizations into a costly cycle of constantly needing to fine-tune or retrain models to keep them relevant, a process that is both technically demanding and financially prohibitive for most use cases, creating a permanent lag between data acquisition and actionable insight.
Third, there is a profound lack of verifiability in traditional AI outputs. When a model provides a summary or an answer, it often feels like a black box. How did it arrive at that conclusion? Which specific moments in the video support its claim? Without the ability to trace an answer back to its source, users cannot fully trust or audit the results. IBM Research highlighted in 2023 that a key benefit of RAG is providing users with access to the model's sources. This is critical in compliance, academic research, and journalism, where source attribution isn't just a feature but a requirement. The inability to cite sources makes it impossible to defend or rely upon the AI's output in high-stakes scenarios.
Finally, the sheer scale of video data presents a daunting challenge for traditional indexing and search. Manually tagging and creating metadata for thousands of hours of video is an intractable problem. While AI can help, models that process entire videos in one go are inefficient and struggle with long-form content. The challenge is to create a system that can intelligently index multimodal AI signals-speech, on-screen text, objects, actions, and faces-in a way that is fast, scalable, and enables complex, semantic queries. Without this, even the most powerful LLMs are left trying to find a needle in a haystack without a map, rendering vast video archives effectively useless.
Deconstructing the Video RAG Pipeline
To appreciate how Video RAG solves these challenges, it's essential to understand its underlying architecture. It's not a single model but a multi-stage pipeline that intelligently connects your video library to the reasoning power of an LLM. This process can be broken down into four key stages, each playing a critical role in transforming raw video into verifiable, AI-generated insights.
The Ingestion and Indexing Phase
Everything begins with preparing the video data. When a new video is introduced to the system, it's not treated as a single, opaque file. Instead, it's deconstructed into its constituent parts. The pipeline uses specialized AI models for each modality: an Automatic Speech Recognition (ASR) model transcribes the audio, an Optical Character Recognition (OCR) model extracts on-screen text, and computer vision models detect objects, scenes, and actions within the video frames. Each of these outputs-a transcript, a list of objects, a scene description-is then passed through an embedding model, which converts the text and image data into numerical representations, or vectors. These vectors capture the semantic meaning of the content, allowing the system to understand concepts and context, not just keywords.
The Role of the Vector Database
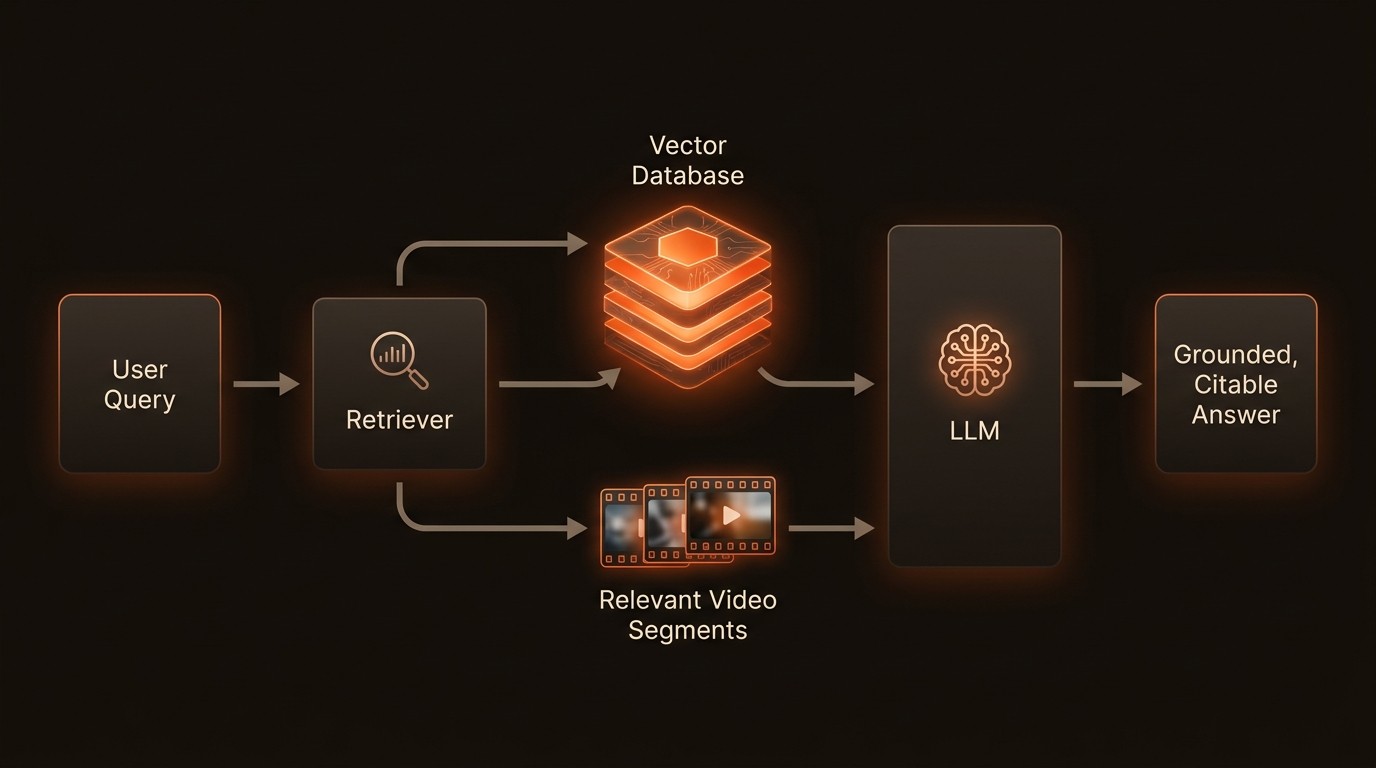
These generated vectors need a specialized home where they can be stored and searched efficiently. This is the role of the vector database. Unlike a traditional database that queries based on exact matches (e.g., WHERE title = 'report.docx'), a vector database finds data based on conceptual similarity. When the vectors from the ingestion phase are stored, they are indexed in a high-dimensional space where similar concepts are located close to one another. Platforms like VideoDB are purpose-built for this task, providing a scalable and optimized environment for storing and retrieving multimodal embeddings. This enables incredibly powerful semantic search capabilities, forming the core of the 'retrieval' mechanism in RAG.
The Retrieval and Augmentation Step
When a user submits a query, such as "Find the moment our CEO discussed Q3 earnings next to a product roadmap," the RAG system springs into action. First, the user's natural language query is converted into a vector using the same embedding model from the ingestion phase. The system then uses this query vector to search the vector database. As explained by YouTube in 2026, RAG retrieves relevant documents using semantic search based on a user's query. In this context, the 'documents' are the indexed video segments whose vectors are closest to the query vector. The system might retrieve the top five most relevant video clips, along with their transcripts and object metadata. This collection of relevant, source-grounded data is then compiled into a detailed context block.
The Generation Phase
In the final stage, the retrieved context is passed to an LLM along with the original user query. The prompt looks something like this:
Now, the LLM's task is simple. It doesn't need to 'remember' anything from its training data. It only needs to synthesize the information provided in the context to generate a direct, factual answer. It can respond: "The CEO discussed Q3 earnings next to a product roadmap in the video clip_04.mp4, specifically at the 1 minute, 15 second mark." This answer is accurate, context-aware, and directly traceable to the source material, effectively solving the core problems of hallucination and lack of verifiability.
Video RAG by the Numbers
Here's what the data reveals about the impact of implementing a Retrieval Augmented Generation strategy for video analysis:
Metric | The RAG-Powered Reality | Business Impact |
|---|---|---|
Factual Accuracy | RAG can significantly reduce hallucinations in LLMs (Databricks). | Increased trust and reliability in AI-generated summaries and insights. |
Data Currency | Implementation ensures the model has access to the most current, reliable facts (IBM Research, 2023). | Enables relevant analysis of new and live video content without model retraining. |
Source Transparency | Provides users with direct access to the model's sources (IBM Research, 2023). | Delivers verifiable, auditable, and defensible AI outputs for compliance and research. |
Contextual Understanding | V-RAG increases accuracy, relevance, and contextual understanding in video generation (AWS, 2026). | Deeper, more nuanced video insights that combine visual and textual cues. |
Search Relevance | Retrieves documents using semantic search based on the user's query (YouTube, 2026). | Moves beyond simple keyword matching to find conceptually related content. |
How RAG Transforms Video Workflows
Implementing a Video RAG system is more than a technical upgrade; it's a fundamental shift in how organizations interact with their video data. By grounding LLMs in verifiable reality, RAG unlocks new capabilities and streamlines existing workflows, turning passive video archives into active, intelligent knowledge bases. This transformation is driven by several key capabilities that directly address the most pressing challenges in video AI.
Achieving Factual Grounding and Eliminating Hallucinations
The most immediate benefit of RAG is its ability to anchor LLM responses to a source of truth. Because the model is provided with the exact snippets of video data relevant to a query, it is constrained to use only that information in its response. This dramatically reduces the risk of hallucination, a critical factor for enterprise adoption. For example, a legal firm using AI for e-discovery can ask, "Did the deponent ever contradict their statement about the project timeline?" A RAG system, backed by a vector database like VideoDB containing all deposition videos, will retrieve the specific clips where the timeline is discussed and generate an answer based solely on that evidence. The result is a reliable, fact-based output that can be trusted in high-stakes legal proceedings.
Enabling Real-Time, Dynamic Knowledge Updates
Traditional AI models require resource-intensive retraining to learn new information. RAG completely sidesteps this bottleneck. According to IBM Research, RAG implementation ensures that the model has access to the most current, reliable facts. When a new video is created-be it a live-streamed press conference, a new piece of user-generated content, or a daily security feed-it simply goes through the ingestion and indexing pipeline. Within minutes, its content is available in the vector database and can be retrieved by the RAG system. The LLM itself doesn't need to be updated. This creates a living knowledge base that grows and evolves with your data, allowing for immediate analysis of new content without the cost and delay of retraining.
Enhancing Multimodal Search and Discovery
Video RAG enables a new paradigm of search that goes far beyond keywords. By converting video, audio, and text into a shared semantic space within a vector database, it allows for complex, cross-modal queries. A developer can build an application that lets users ask questions that require a synthesis of different data types. Consider this pseudo-code for a query:
This level of nuanced discovery is impossible with traditional search tools. It allows content creators, researchers, and analysts to find highly specific moments across vast libraries with conversational ease, unlocking insights that were previously buried within the data. This capability is projected by AWS to increase accuracy and relevance in video understanding and generation significantly by 2026.
Providing Verifiable, Source-Backed Insights
Every answer generated by a Video RAG system comes with built-in citations. Because the retrieval step is a core part of the process, the system knows exactly which video segments were used to formulate the response. A well-designed RAG application doesn't just give you the answer; it presents it alongside the source clips. For a compliance officer auditing training videos, this means they can ask, "Confirm that the new data privacy policy was mentioned in all Q4 onboarding sessions," and receive a 'yes' or 'no' answer, accompanied by links to the exact timestamps in each video where the policy was discussed. This creates a transparent, auditable workflow that builds user trust and satisfies stringent regulatory requirements.
Video RAG in Practice
Theory and architecture are important, but the true value of Video RAG is demonstrated through its real-world applications across various industries. By grounding AI in specific video data, organizations are building smarter, more efficient, and more reliable systems.
Media & Entertainment: Hyper-Specific Content Discovery
A major film studio sits on a century's worth of film and television assets. Their marketing team needs to create a promotional trailer featuring heroic characters in high-stakes situations. Using a Video RAG system, a creative director can move beyond simple metadata tags and make highly specific, semantic queries like, "Show me all clips from our action movies filmed at night where a character says a one-liner right before an explosion." The system would retrieve relevant clips by combining transcript analysis (for the one-liner), visual scene detection (for 'night'), and action recognition (for 'explosion'). This allows the team to discover the perfect shots in minutes rather than the days or weeks it would take with manual review, dramatically accelerating creative workflows.
Corporate Training & Compliance: Automated Auditing
A global financial services firm is required to provide regular and verifiable training on anti-money laundering (AML) regulations to thousands of employees. The compliance department uses a Video RAG system to analyze the entire library of recorded video training sessions. An auditor can ask, "Generate a report of all trainers who failed to mention the '2023 SAR filing update' in their Q4 sessions, and provide timestamps." The RAG system scans the transcripts and returns a precise, actionable list. This automates a previously manual and error-prone auditing process, ensuring 100% coverage and creating a verifiable record of compliance, saving thousands of person-hours annually.
Public Safety & Smart Cities: Incident Analysis
A city's department of transportation uses a network of thousands of traffic cameras. After a hit-and-run incident is reported, investigators need to find the vehicle involved. Instead of manually scrubbing through hours of footage from multiple cameras, they use a Video RAG system. They can issue a query like, "Find all blue sedans that passed through the intersection of 5th and Maple between 2:00 AM and 2:15 AM, and show any that have visible front-end damage." The system leverages object detection (for 'blue sedan'), OCR (for license plates), and anomaly detection (for 'damage') to quickly narrow down the search to a handful of relevant clips. This allows investigators to identify a suspect vehicle in a fraction of the time, improving public safety outcomes.
Industry Voices on RAG's Trajectory
Bob Remeika, CEO and Co-Founder of Ragie, explains RAG as a powerful method for providing context to LLMs that they haven't been trained on, effectively extending their knowledge base to include private or real-time data.
Douwe Kiela, CEO and co-founder of Contextual AI, notes that technologies often seen as competitors to RAG, such as fine-tuning or the use of long context windows, are actually complementary. A well-rounded AI strategy often involves using RAG for factual grounding while leveraging fine-tuning to adapt a model's style or tone.
Your 5-Step Video RAG Implementation Plan
Getting started with Video RAG involves a systematic approach to integrating data, models, and infrastructure. While the architecture is powerful, a phased implementation ensures that the solution is tailored to your specific needs and delivers measurable value. Here is a practical roadmap for building your first Video RAG system.
Define Your Use Case and Data Sources
Before writing any code, clearly identify the problem you want to solve. Are you trying to improve content discovery, automate compliance checks, or analyze security footage? Document your primary video sources, their formats, and their location. This initial step is crucial for scoping the project and defining what success looks like. A clear use case will guide all subsequent technical decisions.
Select Your Multimodal Models
A Video RAG system is a composite AI system. You will need to select a suite of models for the ingestion pipeline. This includes choosing an Automatic Speech Recognition (ASR) model for transcription, computer vision models for object and scene detection, and an embedding model to convert all of this data into vectors. Evaluate open-source options or managed APIs based on their accuracy, speed, and cost for your specific type of video content.
Set Up Your Vector Database
The retriever is the heart of your RAG system, and it relies on a robust vector database. This is where you will store and index the embeddings from your video content. You can choose to self-host an open-source solution or opt for a managed service like VideoDB to handle the complexities of scaling, indexing, and infrastructure management. A managed solution can significantly accelerate your development timeline and reduce operational overhead.
Build the Retrieval and Generation Pipeline
This step involves writing the orchestration logic that connects all the components. You'll need to build the ingestion pipeline that processes new videos and populates the vector database. Then, you'll create the query-side logic that takes a user's input, generates a query vector, retrieves the relevant context from the database, formats the prompt, and sends it to your chosen LLM via its API.
Develop the User Interface and Iterate
Finally, build a user-facing application that allows users to interact with the system. Start with a simple search interface and gather feedback. Continuously monitor the performance of your retrieval system. Are the retrieved chunks of video relevant? Are the LLM's answers accurate? Use user feedback and performance metrics to refine your models, your prompting strategy, and the overall user experience.
Common Questions About Video RAG
Q: What is the difference between Video RAG and simply fine-tuning an LLM?
A: Video RAG and fine-tuning are complementary but solve different problems. Fine-tuning adapts an LLM's style, tone, or knowledge on a static dataset, which is costly and needs to be repeated for new information. RAG, on the other hand, provides the LLM with real-time, external knowledge at query time without altering the model itself, making it ideal for dynamic, fact-based applications where data is constantly changing.
Q: How does RAG handle live or streaming video?
A: For live video, the RAG pipeline processes the stream in near real-time. The stream is broken into small chunks (e.g., 30 seconds), and each chunk is run through the ingestion pipeline to extract features and create embeddings. These embeddings are immediately added to the vector database. This means users can query events that happened just moments ago, as the system's knowledge base is continuously updated as the stream progresses.
Q: Is a vector database mandatory for Video RAG?
A: While you could theoretically use other methods for retrieval, a vector database is considered essential for any serious, scalable Video RAG implementation. Vector databases are specifically designed for high-speed similarity search across millions or billions of vectors, which is the core operation of the retrieval step. Using a traditional database or a simple flat file index would be far too slow and inefficient to be practical for real-world use cases.
Q: What are the main costs associated with implementing a Video RAG system?
A: The primary costs can be broken into three categories. First, the computational cost of the ingestion pipeline, which involves running multiple AI models to process videos. Second, the cost of using a managed vector database or the infrastructure cost of hosting your own. Third, the cost of LLM API calls for the generation step. Careful optimization of each stage is key to managing the overall operational cost.
Q: How does Video RAG improve upon traditional metadata tagging?
A: Traditional metadata tagging is often manual, slow, and limited to a predefined set of keywords or tags. Video RAG automates the 'tagging' process by creating rich, semantic vector embeddings for all aspects of the video content. This allows for dynamic, conversational search that can find concepts and relationships that were never explicitly tagged, providing a much deeper and more flexible way to explore video content.
Key Takeaways
RAG grounds LLMs in reality: By retrieving relevant video data first, RAG significantly reduces hallucinations and ensures answers are based on verifiable facts.
Overcomes data staleness: RAG allows LLMs to access the most current information from your video library without costly retraining, making it ideal for dynamic content.
A vector database is crucial: Systems like VideoDB are the core engine for the 'retrieval' step, enabling efficient semantic search across multimodal AI data.
Enables true multimodal search: Video RAG allows users to ask complex, conversational questions that combine visual, audio, and textual elements.
Provides auditable AI: Every answer generated by a RAG system can be traced back to the source video clips, building trust and enabling verification.









