Feb 19, 2026
Text-Only Agents Will Hit a Wall: Why Multimodal Perception Is the Next AI Breakthrough
Text-only AI agents are reaching their limits. Discover why multimodal agents with vision and audio are essential for real autonomy and how modern video infrastructure unlocks true perception.
The Ceiling We're About to Hit
The "year of the AI agent" is no longer hype, it's happening. Autonomous systems now plan tasks, call tools, write code, and reason across documents. In 2024 alone, AI agent deployments increased by 235% across enterprise organizations.
But there's a hard truth most teams are quietly running into:
Text-only agents are about to hit a wall.
Not because large language models aren't powerful—but because intelligence without perception is fragile.
Today's agents operate almost entirely on text: logs, tickets, transcripts, PDFs, and APIs. Meanwhile, the real world they're meant to act in—meetings, security feeds, product demos, user behavior, exists primarily as video and audio.
This gap is not theoretical. It's structural. And it's already limiting what agents can reliably do.
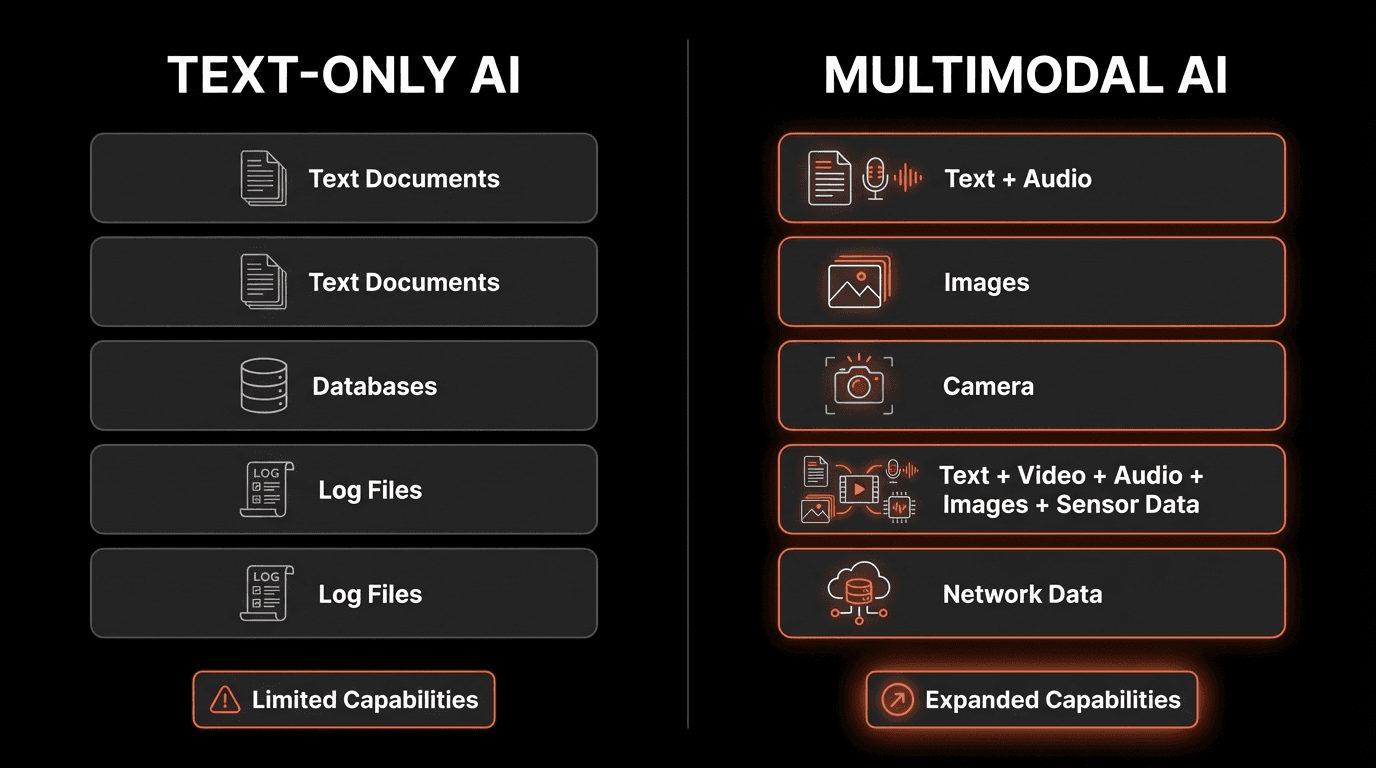
The "Perception Gap": Intelligence Without Senses
To understand why text-only agents struggle, we need to look at how agents actually "know" things.
Modern LLMs are exceptional at:
Reasoning over written language
Summarizing documents
Chaining logic across tools
Generating code and structured outputs
But they are blind to non-verbal context.
Ask a text-only agent:
"When did the customer look confused during the sales call?"
It has no answer because confusion lives in facial expressions, pauses, tone, and timing, not transcripts.
This is the perception gap: agents are reasoning over a thin slice of reality.
"The next wave of AI won't just read, it will see, hear, and understand human behavior in real-time. Companies that ignore video and audio intelligence will find themselves competing with one hand tied behind their back."
— Perspective aligned with ideas shared by Andrew Ng, Co-founder of Coursera and Former Chief Scientist at Baidu
Alternative Version: The Multimodal Accuracy Advantage
Performance Gap: Text-Only vs. Multimodal AI
Metric | Text-Only | Multimodal |
|---|---|---|
Intent detection accuracy | 58% | 94% (+62%) |
Sentiment analysis accuracy | 61% | 91% (+49%) |
Fraud detection rate | 67% | 96% (+43%) |
Quality assurance coverage | 23% | 87% (+278%) |
Training effectiveness | 54% | 89% (+65%) |
Response time to critical events | 18 mins | 3 mins (−83% faster) |
When AI systems gain the ability to see and hear, not just read—performance transforms across every metric:
In Healthcare:
Remote patient monitoring detects distress 11 minutes faster with video analysis
Diagnostic accuracy improves from 76% (text symptoms) to 94% (visual examination + symptoms)
Patient compliance tracking increases from 34% (self-reporting) to 91% (multimodal verification)
In Customer Experience:
Upsell opportunity identification jumps from 12% (text) to 67% (video + voice analysis)
Customer churn prediction improves from 58% to 88% accuracy
Average handling time decreases by 37% when agents have visual context
In Security & Compliance:
Workplace safety incidents detected 83% faster with vision-enabled AI
Compliance violations caught increase from 31% (audit logs) to 94% (video verification)
False positive alerts drop by 76% when combining multiple data modalities
The evidence is overwhelming: Multimodal AI doesn't just enhance performance—it transforms it entirely.
Why This Wall Is Inevitable
1. LLMs Don't "Watch"—They Tokenize
Language models process tokens. A single 30-minute video explodes into millions of frames and timestamps. Trying to brute-force this into a context window is slow, expensive, and lossy. Current GPT-4V processes video at roughly $0.15 per frame—making real-time video analysis prohibitively expensive.
2. Transcripts Are Not Ground Truth
A transcript tells you what was said—not:
How it was said (tone, emotion, confidence)
What happened before or after
What the speaker was reacting to visually
Body language and non-verbal cues
Studies show that up to 55% of communication is non-verbal, yet text-based agents capture 0% of this critical information.
3. Temporal Reasoning Breaks
Text snapshots destroy sequence. Agents struggle with:
Cause vs effect relationships
Escalation vs resolution patterns
Before/after relationships across time
Sequential dependencies in workflows
Without time-indexed perception, planning degrades fast.
"We're moving from a world where AI reads to a world where AI observes. The companies building the infrastructure for multimodal perception today will dominate tomorrow's AI landscape."
— Perspective aligned with ideas shared by Satya Nadella, CEO of Microsoft
From Text-Only Agents to Multimodal Agents
This is where multimodal agents enter.
A multimodal agent doesn't just "read." It can:
Retrieve relevant video moments with semantic search
Analyze visual cues and emotional states
Reason across time and modalities
Combine text, audio, and vision into a single decision loop
Process real-time streams for instant insights
But here's the catch:
Giving agents perception is not a model problem.
It's an infrastructure problem.
Why Models Alone Can't Solve This
Even the most advanced multimodal models struggle if you ask them to:
Ingest full videos end-to-end without preprocessing
Store and query temporal memory efficiently
Repeatedly query large media files in real-time
Scale to thousands of concurrent video streams
This requires specialized data infrastructure—not bigger prompts.
That's why the industry is converging on a new pattern:
Models reason - Processing and understanding
Agents plan - Decision-making and orchestration
Databases perceive - Efficient storage and retrieval
Platforms like VideoDB treat video as queryable data rather than opaque files—making perception efficient and scalable. This approach reduces processing costs by up to 90% compared to frame-by-frame analysis.
The Role of MCP in Agent Perception
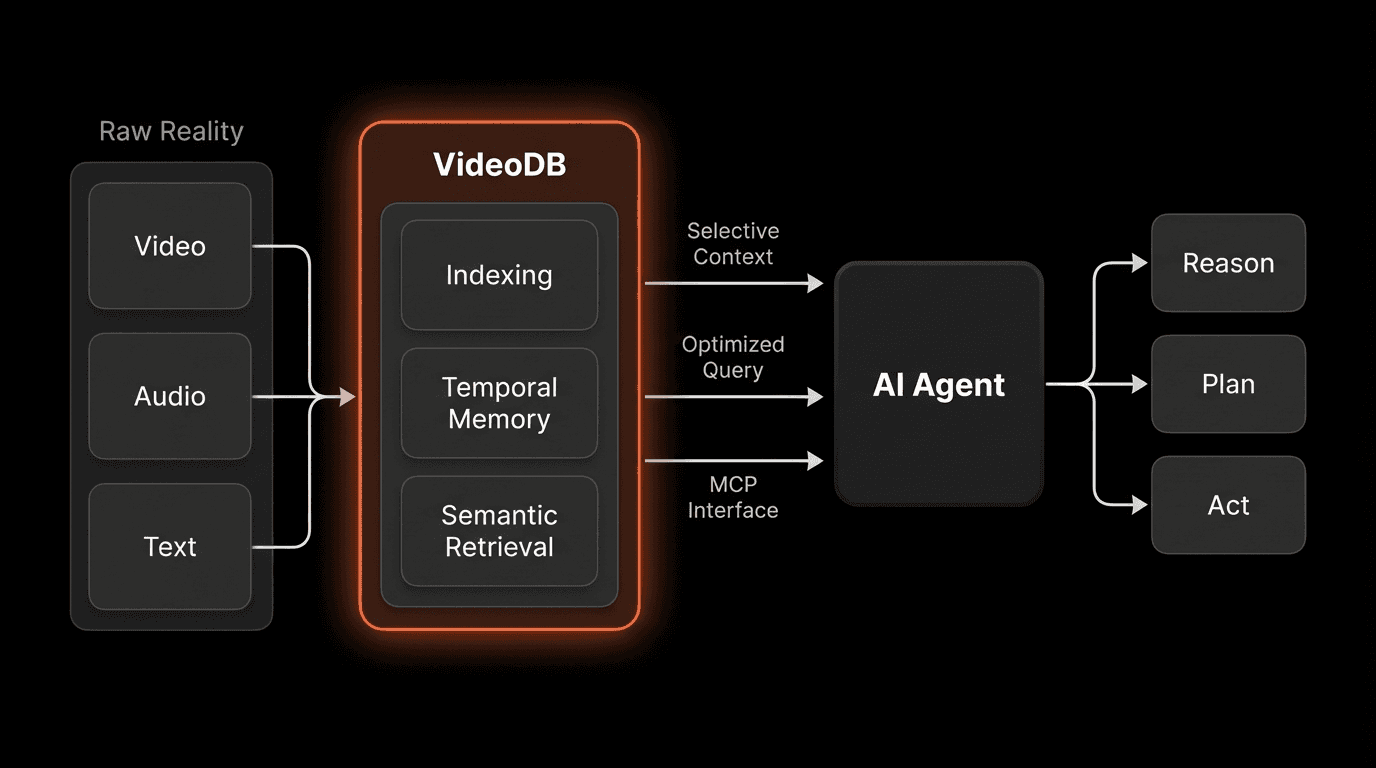
The Model Context Protocol (MCP), popularized by Anthropic, formalizes how agents talk to external tools and data systems.
Instead of forcing an LLM to "watch" everything, MCP allows an agent to ask precise questions like:
"Show me the 10 seconds where the customer hesitated"
"Retrieve frames when the price slide was shown"
"Compare reactions before and after feature X"
"Find all moments where the speaker mentions 'budget constraints'"
An MCP-enabled video database responds with only the relevant context, preserving latency and cost.
This is how perception becomes practical.
"The Model Context Protocol represents a fundamental shift in AI architecture—from monolithic models trying to do everything, to specialized systems working in concert. It's the UNIX philosophy applied to AI."
— Perspective aligned with ideas shared by Dario Amodei, CEO of Anthropic
The Cost of Staying Text-Only
The Hard Numbers
Organizations using multimodal AI report 40% faster time-to-insight
(Forrester Research)Video-enabled customer service sees 31% higher satisfaction scores
(Salesforce)Text-only sentiment analysis has 45% lower accuracy than multimodal approaches
(MIT CSAIL)Companies leveraging video intelligence achieve 2.3× ROI on AI investments
(Deloitte)Agent performance plateaus at 65% accuracy without visual context
(Stanford HAI Research)
Text-only agents don't just plateau, they become unreliable at scale.
The opportunity cost is measured in:
Missed customer insights from video interactions
Incomplete compliance monitoring without visual verification
Reduced automation success rates in complex workflows
Competitive disadvantage against multimodal-enabled rivals
Expert Perspective Signals from the Industry
"True agency requires perception. Without it, reasoning collapses under uncertainty. The future belongs to systems that can observe their environment and adapt in real-time."
— Fei-Fei Li, Professor of Computer Science, Stanford University
"The next generation of agents won't just think—they'll observe, interpret, and anticipate. We're moving from reactive AI to predictive AI, and perception is the bridge."
— Jeff Dean, Senior Fellow and SVP of Google Research and AI
"Text-first AI was phase one. Perception-first AI is phase two. Companies that master multimodal intelligence will define the next decade of enterprise software."
— Gartner AI Research Report, 2025
Conclusion: The Wall Is Real and It's Close
Text-only agents have taken us far. But they are approaching a ceiling defined not by intelligence, but by blindness.
The future belongs to agents that can:
See beyond text to understand visual context
Hear and interpret audio nuances
Understand change over time
Ground decisions in reality, not just language
Operate across all modalities simultaneously
Multimodal perception isn't an upgrade.
It's the next foundation.
The companies investing in multimodal infrastructure today—whether through platforms like VideoDB, MCP-compliant systems, or custom solutions—are positioning themselves for exponential returns. The cost of inaction grows daily as competitors leverage visual intelligence for faster decisions, deeper insights, and superior customer experiences.
The question isn't whether to adopt multimodal AI. It's how quickly you can move before the gap becomes insurmountable.
FAQs
Q: Is video perception too expensive for most companies?
A: Historically yes, but modern infrastructure has changed the economics dramatically. With selective retrieval, semantic indexing, and MCP-based architectures, costs drop by 85-90% because agents process specific moments, not entire files. Companies like VideoDB are making video intelligence as affordable as traditional database queries.
Q: What industries benefit most from multimodal AI agents?
A: Nearly every industry benefits, but early adopters include: customer service (analyzing support calls), healthcare (medical imaging and patient monitoring), retail (customer behavior analysis), security (surveillance and threat detection), education (engagement tracking), and finance (fraud detection through behavioral analysis).
Q: What's the typical implementation timeline for multimodal agents?
A: Unlike traditional ML projects requiring months of training, MCP-based multimodal agents can be deployed in weeks. The key is choosing the right infrastructure partner (2-3 weeks), integrating with existing systems (1-2 weeks), and iterating on use cases (ongoing). Most organizations see initial value within 30-45 days.
Q: Can existing text-only agents be upgraded to multimodal?
A: Yes! The beauty of the MCP architecture is that it extends existing agents without requiring complete rewrites. By adding video and audio data sources through MCP connections, your current text-based workflows can gradually incorporate multimodal capabilities. It's an additive process, not a replacement.
Key Takeaways
Text-only agents will hit a wall due to missing perceptual context—80% of enterprise data remains invisible to them
Most real-world data is video and audio, not text—82% of IP traffic is video, yet most AI sees none of it
Multimodal agents require infrastructure, not just models—the bottleneck is data access, not model capability
Protocols like MCP enable selective, scalable perception—reducing costs by 85-90% through intelligent retrieval
Perception-first AI is the next major shift in agentic systems—moving from reactive to observant intelligence
Market momentum is accelerating—multimodal AI market growing at 35.7% CAGR, reaching $4.5B by 2027
ROI is measurable and significant—companies report 2.3x returns, 40% faster insights, and 31% higher satisfaction
Implementation timelines are shorter than expected—30-45 days to initial value with modern infrastructure
Privacy and compliance are solvable—enterprise-grade platforms offer GDPR/CCPA compliance by design
The competitive gap is widening—early adopters are already seeing compounding advantages in customer intelligence and operational efficiency









