Apr 16, 2026
Unlock Video Insights: Embedding and Indexing for Smarter Search
Discover how video embedding and indexing transform raw video into searchable assets. Learn the AI techniques to unlock deep insights and build smarter search applications.
Beyond the Play Button: The Data Trapped in a Billion Hours of Video
Every single day, people watch over a billion hours of video on YouTube alone. This staggering figure, confirmed by YouTube in 2024, represents a colossal volume of unstructured data. When you factor in enterprise video, security footage, social media, and streaming services, the scale becomes almost incomprehensible. Cisco predicted back in 2019 that video would account for 82% of all consumer internet traffic by 2022, a milestone we have long since surpassed. This deluge of visual and auditory information holds immense potential value, from business intelligence and security insights to personalized content discovery and educational resources. Yet, for most organizations and developers, this value remains locked away, trapped behind a simple play button.
The fundamental challenge lies in search. Traditional search methods, built for text, are profoundly inadequate for video. They rely on manually created metadata-titles, descriptions, and tags-which are often sparse, inconsistent, or completely missing. This approach treats the video file as a black box, ignoring the rich tapestry of information contained within its frames and audio track. As a result, finding a specific moment, object, or spoken phrase within a vast video library is like searching for a needle in a haystack, only the haystack is growing exponentially every second. This is the critical bottleneck preventing us from truly leveraging the world's dominant form of content.
To solve this, we must shift our perspective from simply storing video to truly understanding it. This requires a new paradigm for video search, one that moves beyond superficial metadata and engages directly with the content itself. By applying advanced AI techniques like video embedding and video indexing, we can transform opaque video files into structured, queryable data assets. This allows us to build applications that can find not just a video, but the precise moments within a video that matter most. It’s about making video as searchable as text, unlocking a new frontier of data-driven applications and insights that were previously impossible to achieve.

The High Cost of Unstructured Video Data
Operating with an unsearchable video archive isn't just an inconvenience; it's a significant technical and financial liability. The inability to efficiently access and analyze video content introduces friction, creates operational blind spots, and stifles innovation. For developers and data scientists, the pain points are acute and multifaceted, each carrying a tangible cost. The core issue is that without intelligent indexing, video is a passive asset rather than an active source of intelligence, leading to wasted resources and missed opportunities across the board.
First, the reliance on manual tagging is a losing battle against scale. Manually watching, annotating, and tagging even a single hour of video can take several hours of focused labor. This process is not only slow and expensive but also prone to human error and subjective interpretation. An organization with thousands of hours of video content faces an impossible task. The result is that most video archives are either untagged or poorly tagged, rendering them effectively invisible to internal search tools. This manual bottleneck directly translates to delayed projects, underutilized assets, and a significant competitive disadvantage in a world where speed to insight is paramount.
Second, the keyword mismatch problem plagues traditional systems. When search is limited to file names and brief descriptions, it fails to capture the nuance and context of the actual content. A user might search for "product demo of the new dashboard," but if the video's metadata only contains the project code name, the search will fail. This semantic gap means that valuable content remains undiscovered. According to BrightEdge, search is the number one driver of traffic to content sites, and HubSpot found that video can increase organic traffic by 157%. When your own internal or external search fails, you are leaving this value on the table, frustrating users and diminishing the ROI of your content creation efforts.
Third, the lack of contextual understanding leads to irrelevant and frustrating search experiences. A simple query for "deployment" in a corporate training library could return videos about software deployment, troop deployment, or deploying a new marketing strategy. Without the ability to understand the context-the surrounding words, the objects on screen, the speaker's role-the search engine cannot disambiguate the user's intent. This forces users to manually sift through dozens of irrelevant results, wasting time and eroding their confidence in the system. True semantic search is required to understand that a search for "server configuration best practices" should surface a specific segment from a technical deep-dive video, even if those exact words are never spoken in that precise order.
From Pixels to Vectors: The Technology Behind Video Intelligence
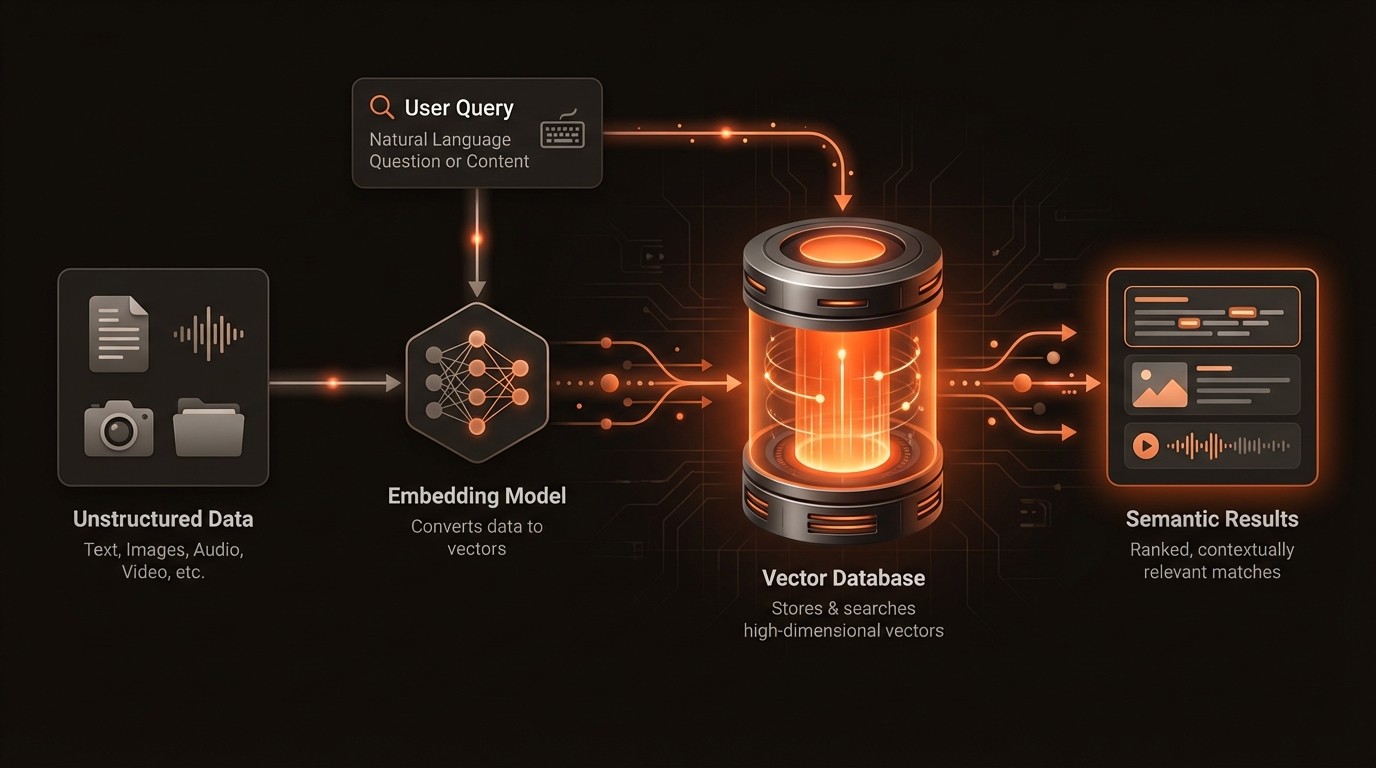
To make video truly searchable, we need to teach machines to "watch" and understand content in a way that mirrors human perception. This is achieved by converting the unstructured data of video-pixels, audio waves, and text-into a structured, mathematical format that computers can compare and analyze. The core technologies driving this transformation are video embedding and video indexing, which work together to create a powerful foundation for intelligent search. These concepts are not just theoretical; they are the practical engine behind modern video AI platforms like VideoDB.
What is Video Embedding?
Video embedding is the process of using deep learning models to convert a piece of content, such as a video clip or an image, into a high-dimensional numerical vector. This vector, or "embedding," serves as a compact, semantic signature of the content. The magic of embeddings is that they capture meaning and context. For example, video clips of a "golden retriever catching a frisbee" and a "labrador chasing a ball" will have vectors that are mathematically close to each other in the vector space, while a clip of a "city skyline at night" will have a vector that is far away. This is accomplished by training models on massive datasets, allowing them to learn the complex relationships between visual and auditory patterns.
The Power of Multimodality
Modern video analysis goes beyond just the visual stream. A truly comprehensive understanding requires a multimodal approach, integrating information from different sources within the video. This includes transcribing the audio track into text (speech-to-text), identifying objects and their positions in each frame (object detection), recognizing faces, and even reading text that appears on screen (Optical Character Recognition or OCR). Each of these data streams can be embedded into its own vector or combined into a single, powerful multimodal embedding. This holistic approach allows for incredibly nuanced queries, such as finding a scene where a specific person is talking about a particular product, with that product's logo visible in the background.
The Role of Video Indexing
Once you have converted your video library into a collection of vectors, you need an efficient way to search through them. This is where video indexing comes in. Simply comparing a query vector to every other vector in a large database (a brute-force search) is computationally expensive and slow. Instead, specialized vector databases use algorithms like Hierarchical Navigable Small World (HNSW) or Inverted File (IVF) to create an index. This index intelligently organizes the vectors so that finding the nearest neighbors to a query vector can be done in milliseconds, even with billions of entries. This combination of rich embeddings and fast indexing is what makes real-time semantic video search possible.
Video's Data Deluge: A Quantitative Look
Here's what the data reveals about the scale of video and the importance of making it searchable:
Metric | Statistic | Implication for Search |
|---|---|---|
Global Internet Traffic | 82% of all consumer internet traffic is video (Cisco, 2019) | The vast majority of new data is unsearchable by default, creating a massive intelligence gap. |
Website Popularity | YouTube is the 2nd most popular website globally (Alexa, 2024) | User behavior is overwhelmingly centered on video, making effective video search a critical user experience feature. |
Daily Consumption | Over 1 billion hours of video are watched on YouTube daily (YouTube, 2024) | The sheer volume of content makes manual discovery impossible; automated, intelligent search is the only scalable solution. |
Content Discovery | Search is the #1 driver of traffic to content sites (BrightEdge, 2019) | If your video content isn't indexed semantically, you are missing the primary channel for user acquisition and engagement. |
SEO Impact | Video increases organic traffic from search by 157% (HubSpot, 2023) | Properly indexed video content directly translates to better visibility and higher traffic, both externally and internally. |
Business ROI | 87% of video marketers report a positive ROI from video (Wyzowl, 2024) | Maximizing this ROI depends on making video assets discoverable and reusable long after their initial publication. |
Building a Smarter Search Engine for Video
The transition from a passive video archive to an active intelligence hub requires a systematic approach to data processing and retrieval. It involves building a pipeline that automates the extraction of insights and makes them instantly accessible through a flexible, semantic search interface. This is not just about adding a search bar; it's about re-architecting how you interact with video data at a fundamental level. Platforms like VideoDB are designed to manage this entire lifecycle, from ingestion and analysis to indexing and querying, providing the infrastructure needed to build sophisticated video applications.
Automated Multimodal Metadata Generation
The first step is to eliminate the manual tagging bottleneck. A modern video intelligence pipeline automates this by applying a suite of AI models to every video. This process, often called feature extraction, generates rich, time-coded metadata. For example, a speech-to-text model creates a full transcript, an object detection model identifies and tags every object in every scene (e.g., 'car', 'laptop', 'person'), and an OCR model extracts any text visible on screen, such as presentation slides or product labels. This automated metadata forms a comprehensive, structured layer of information that describes the video's content moment by moment, providing a robust foundation for search.
Implementing True Semantic Search
With rich metadata and vector embeddings in place, you can move beyond simple keyword matching to true semantic search. This means users can search using natural language and conceptual queries. Instead of searching for "cat," a user can search for "funny animal videos," and the system will return clips of cats, dogs, and other animals engaged in amusing behavior because their vector embeddings are close in the semantic space. This is powered by vector similarity search. A query is converted into a vector, and the system finds the vectors in its index that are most similar. This approach is far more intuitive and powerful, mirroring how humans think and recall information.
Scene-Level Indexing and Retrieval
A critical capability for video is the ability to search within the content, not just for it. Effective video indexing doesn't just create one embedding for an entire hour-long video. Instead, it breaks the video down into logical scenes or short time-based chunks and creates an embedding for each one. This temporal, or scene-level, indexing allows the search engine to return not just a relevant video, but the exact timestamp where the relevant content begins. For a user, this is the difference between being handed a 300-page book and being pointed to the exact paragraph that answers their question. This precision is essential for applications in e-learning, compliance, and media monitoring, where finding specific moments is the primary goal. A platform like VideoDB handles this segmentation and indexing automatically.
Video Search in Action: From Media to Manufacturing
The practical applications of intelligent video search span nearly every industry, transforming workflows that were previously manual, time-consuming, or impossible. By turning video into a queryable data source, organizations can enhance security, accelerate content creation, and improve knowledge sharing. The common thread across these use cases is the ability to pinpoint specific moments of value within massive video archives, driving efficiency and unlocking new capabilities.
Media and Entertainment
For media companies, content is their core asset. Intelligent search allows them to manage and monetize their archives more effectively. Content moderation teams can automatically flag and review footage for compliance violations, such as brand safety issues or explicit content, by searching for specific visual or spoken cues. On the content discovery side, recommendation engines can move beyond user viewing history to analyze the actual content of shows. They can identify scenes with similar moods, settings, or character interactions to provide highly relevant "watch next" suggestions, increasing user engagement and retention.
E-Learning and Corporate Training
Enterprises produce thousands of hours of training videos, webinars, and all-hands meetings. These recordings contain a wealth of institutional knowledge, but it's often inaccessible. With semantic search, an employee can ask, "Where did the CEO discuss the new market expansion strategy?" and be taken to the exact moment in a two-hour meeting recording. This transforms the corporate video library from a passive archive into an active, on-demand knowledge base. New hires can quickly find answers to their questions, and existing employees can refresh their knowledge on specific procedures without having to re-watch entire training modules, saving thousands of hours of productivity.
Security and Public Safety
In the security sector, analysts are often tasked with reviewing countless hours of surveillance footage to find a single event. Intelligent video search dramatically accelerates this process. An operator can search for "a person wearing a red jacket entering through the back door between 2 AM and 4 AM" across hundreds of camera feeds simultaneously. The system can also be configured to send real-time alerts for specific events, such as a vehicle entering a restricted area or an unattended bag being left behind. This proactive capability enhances situational awareness and allows security teams to respond to incidents faster and more effectively.
Industry Voices on Video's Future
Industry leaders have long recognized the forces shaping the video landscape. Nilay Patel, Editor-in-chief at The Verge, noted in The Verge that YouTube's recommendation algorithm plays a significant role in shaping user experience and content discovery, highlighting the power of algorithmic curation in navigating massive content libraries. (2019) This underscores the commercial and cultural importance of moving beyond simple search boxes to more sophisticated, context-aware systems that can understand and rank video content effectively.
From a technical standpoint, the foundation of this technology rests on progress in machine learning. Dr. Fei-Fei Li, a leading professor at Stanford University, emphasized in Stanford News the critical importance of large, well-labeled datasets in advancing the fields of computer vision and video understanding. (2017) Her work points to the engine that powers video embedding: robust AI models trained on diverse data, which are essential for creating the nuanced vector representations that make semantic search possible. Together, these perspectives show a convergence of user demand for better discovery and the technical capability to deliver it.
Your Five-Step Guide to Intelligent Video Search
Implementing an intelligent video search solution can seem daunting, but breaking it down into a structured roadmap makes the process manageable. The key is to start with a clear business objective and iteratively build capabilities. Whether you use a comprehensive platform like VideoDB or assemble your own solution from individual components, following these steps will help ensure a successful implementation.
Define Your Core Use Case: Before writing any code, clearly identify the problem you are trying to solve. Are you building a content discovery tool for a media archive? An internal knowledge base for training videos? A compliance monitoring system? Your specific goal will dictate the types of AI models you need, the required search precision, and the user interface you will build. Document the key pain points of the current workflow to establish a baseline for measuring success.
Select and Configure Your AI Models: Based on your use case, choose the appropriate AI models for feature extraction. At a minimum, you will likely need speech-to-text for audio transcription. You may also need object detection, facial recognition, or OCR models. Evaluate pre-trained models for their accuracy on your specific type of content and decide whether you need to fine-tune them on your own data for better performance.
Establish a Scalable Data Pipeline: Design an automated workflow for ingesting and processing your videos. This pipeline should handle video transcoding, trigger the various AI models for analysis, generate the embeddings, and store the resulting metadata and vectors. This should be a scalable, event-driven architecture that can handle both the backfill of your existing library and the continuous processing of new video content as it arrives.
Choose an Indexing and Search Platform: This is the heart of your search system. You need a specialized vector database to store and index your video embeddings for fast retrieval. This is where a managed solution like VideoDB can dramatically accelerate development, as it provides a fully integrated environment for video processing, vector indexing, and semantic search APIs, abstracting away the complex infrastructure management.
Build the User Interface and Iterate: With the backend in place, focus on the front-end search experience. Create an intuitive interface that allows users to perform semantic searches, filter results, and play videos directly from the relevant timestamp. Deploy an initial version to a pilot group of users, gather feedback on the relevance of the search results and the usability of the interface, and iterate continuously to improve the system.
Common Questions About Video Embedding and Indexing
Q: What is the difference between traditional keyword search and semantic video search?
A: Traditional keyword search matches the exact text in your query to the text in a video's title, description, or manual tags. It's literal and lacks context. Semantic search, powered by embeddings, understands the intent and conceptual meaning behind your query. It can find relevant content even if the exact keywords are not present, by matching the meaning of your query to the meaning of the video content itself.
Q: How are video embeddings created?
A: Video embeddings are created by processing video clips through a deep learning model, typically a neural network. The model, which has been pre-trained on millions of videos, analyzes the visual and auditory patterns and outputs a dense vector of numbers. This vector represents the video's content in a high-dimensional space, where semantically similar videos are located close to one another. This process is automated and forms the basis for semantic understanding.
Q: Is this technology expensive to implement from scratch?
A: Building a robust video search system from the ground up can be resource-intensive. It requires expertise in machine learning, data engineering, and infrastructure management. Costs include GPU resources for running AI models, storage for videos and metadata, and engineering time. This is why many developers opt for managed platforms like VideoDB, which handle the underlying complexity and provide a more cost-effective, consumption-based pricing model.
Q: What kind of hardware is needed to run these AI models?
A: Running deep learning models for video analysis, especially at scale, typically requires powerful Graphics Processing Units (GPUs). GPUs are designed to handle the parallel computations required for neural network inference efficiently. A production-grade pipeline often involves a cluster of GPU-enabled servers to process video streams in a timely manner. Cloud providers offer on-demand GPU instances, but managing this infrastructure can be complex.
Q: How does a platform like VideoDB simplify this process?
A: VideoDB simplifies the process by providing an end-to-end, managed platform for video AI. It abstracts away the complexity of building and maintaining the data pipeline, running AI models, and managing a vector database. Developers can use a simple API to upload videos, and the platform automatically handles the analysis, embedding, and indexing. This allows teams to focus on building their application's features instead of wrestling with the underlying infrastructure.
Key Takeaways
Video constitutes over 82% of internet traffic, but most of it is unstructured and unsearchable, representing a massive untapped source of data.
Video embedding converts video content into numerical vectors that capture semantic meaning, while video indexing organizes these vectors for fast, efficient search.
Semantic search allows users to query video content based on concepts and natural language, providing far more relevant results than traditional keyword matching.
A multimodal approach, analyzing visuals, audio, and on-screen text, creates a comprehensive understanding of video content, enabling highly specific and powerful queries.
Managed platforms like VideoDB abstract away the complex infrastructure required for video AI, enabling developers to build intelligent search applications more quickly and cost-effectively.









