Apr 16, 2026
Unlock Video Insights: The Power of Vector Databases for Video Data
Explore how vector databases are revolutionizing video data analysis. Learn to leverage vector embeddings and similarity search for advanced video analytics.
Beyond the Timestamp: Searching Video by Meaning, Not Metadata
According to a 2020 report from Seagate, video data now comprises a significant and rapidly growing portion of the world's data. Every minute, hundreds of hours of new video are uploaded, streamed, and archived. This deluge of visual information represents an immense, largely untapped reservoir of insight for businesses, researchers, and creators. Yet, for decades, our ability to access this information has been constrained by a fundamental limitation: we search for video using words, but video itself is made of pixels and soundwaves. This disconnect has forced us to rely on manual tags, titles, and descriptions-a brittle and unscalable layer of metadata that barely scratches the surface of the content within.
The core challenge lies in bridging this semantic gap. How do you find a specific moment in a video without knowing the exact timestamp or a pre-assigned keyword? How can a system understand a query like "find all scenes with a tense negotiation" or "show me every clip where a person is smiling at a product"? Traditional search methods fail here because they lack contextual understanding. They can find a video titled "Tense Negotiation Scene," but they cannot identify the visual and auditory cues of tension within an untagged video file. This is the frontier of modern video analytics, moving beyond simple event logging and into the realm of true content comprehension.
This is where vector databases enter the picture, offering a fundamentally new paradigm for interacting with video data. By transforming raw visual and audio information into rich, mathematical representations called vector embeddings, these specialized databases allow us to search video based on its semantic meaning. Instead of matching keywords, we can now find content based on conceptual similarity. This capability is not just an incremental improvement; it's a foundational shift that unlocks the true potential of the world's fastest-growing data type, enabling applications that were once the domain of science fiction. It's time to move past the limitations of metadata and start a direct conversation with our video content.
The Unstructured Data Dilemma: Why Traditional Video Search Fails
For any organization that works with video at scale, the limitations of conventional data management systems are a source of constant friction and missed opportunity. The problem isn't a lack of data; it's the inability to efficiently query and extract value from it. This challenge manifests in several critical pain points that hinder innovation and drive up operational costs. These issues stem from a core mismatch: trying to fit high-dimensional, unstructured video data into rigid, text-oriented database structures that were never designed for the task.
First is the overwhelming scalability bottleneck. Relational or document-based databases crumble under the sheer volume and velocity of video data. Indexing and querying petabytes of high-resolution footage using traditional methods is computationally prohibitive. The process is agonizingly slow, and the infrastructure costs required to maintain even a semblance of performance become unsustainable. As a result, vast archives of valuable video content become "write-once, read-never" data graveyards, simply because the tools to explore them effectively do not scale. This directly impacts a company's ability to leverage its own historical data for training new AI models or discovering long-term trends.
Second, and perhaps most significant, is the semantic gap. Traditional databases operate on exact matches of structured data-text strings, numbers, and booleans. They cannot comprehend the nuanced, abstract concepts inherent in visual content. A search for "brand logo in a positive context" is meaningless to a system that only understands file names and keyword tags. This forces teams to rely on extensive, manual tagging, a process that is not only slow and expensive but also inherently subjective and inconsistent. The result is a search experience that is frustratingly literal, returning irrelevant results or, worse, missing critical information that wasn't tagged with the precise keyword used in the query.
This reliance on manual labor leads directly to the third pain point: operational inefficiency. The process of watching, annotating, and logging video content is a massive resource drain. It creates a human bottleneck that simply cannot keep pace with the rate of content creation. For media companies, this means delays in content production workflows. For security firms, it means critical events might be missed in the hours it takes to review footage. This manual effort is not a one-time cost; it's a continuous operational expense that grows linearly with the size of the video archive, directly impacting the bottom line and diverting skilled personnel from higher-value analytical tasks.
Finally, there is the latency barrier to real-time applications. As organizations increasingly use video analytics for security, surveillance, and business intelligence, the need for instantaneous results is paramount. A traditional database query might take minutes or even hours to scan a large video library, which is far too slow for applications like live threat detection, real-time content moderation, or dynamic ad insertion. This high latency renders a whole class of valuable, time-sensitive applications impossible, forcing organizations to operate reactively rather than proactively. The inability to analyze video streams in near real-time represents a massive competitive disadvantage in a world that demands immediate insights.
From Pixels to Vectors: The Technology Behind Semantic Video Search
To overcome the limitations of traditional video search, we need to change how machines perceive and index video content. The breakthrough lies in a combination of deep learning and specialized data structures that allow us to move from literal, keyword-based indexing to a more fluid, conceptual understanding. This process revolves around two core technologies: vector embeddings and the vector databases built to manage them. Together, they form the foundation of modern semantic search, enabling us to query the meaning embedded within the pixels themselves.
What are Vector Embeddings?
At its heart, a vector embedding is a numerical representation of unstructured data. Advanced AI models, such as multimodal models like CLIP or convolutional neural networks (CNNs) like ResNet, are trained on vast datasets to understand the features and patterns within images, text, and audio. When you feed a piece of data-like a single frame from a video-into one of these models, it outputs a list of numbers called a vector. This vector, which can have hundreds or even thousands of dimensions, serves as a dense, mathematical fingerprint that captures the semantic essence of the input. For example, frames showing a golden retriever in a park and a labrador on a beach will produce vectors that are mathematically similar, even if the pixels are completely different. As noted by NVIDIA in 2023, it is these embeddings that truly enable the semantic search and analysis of video content.
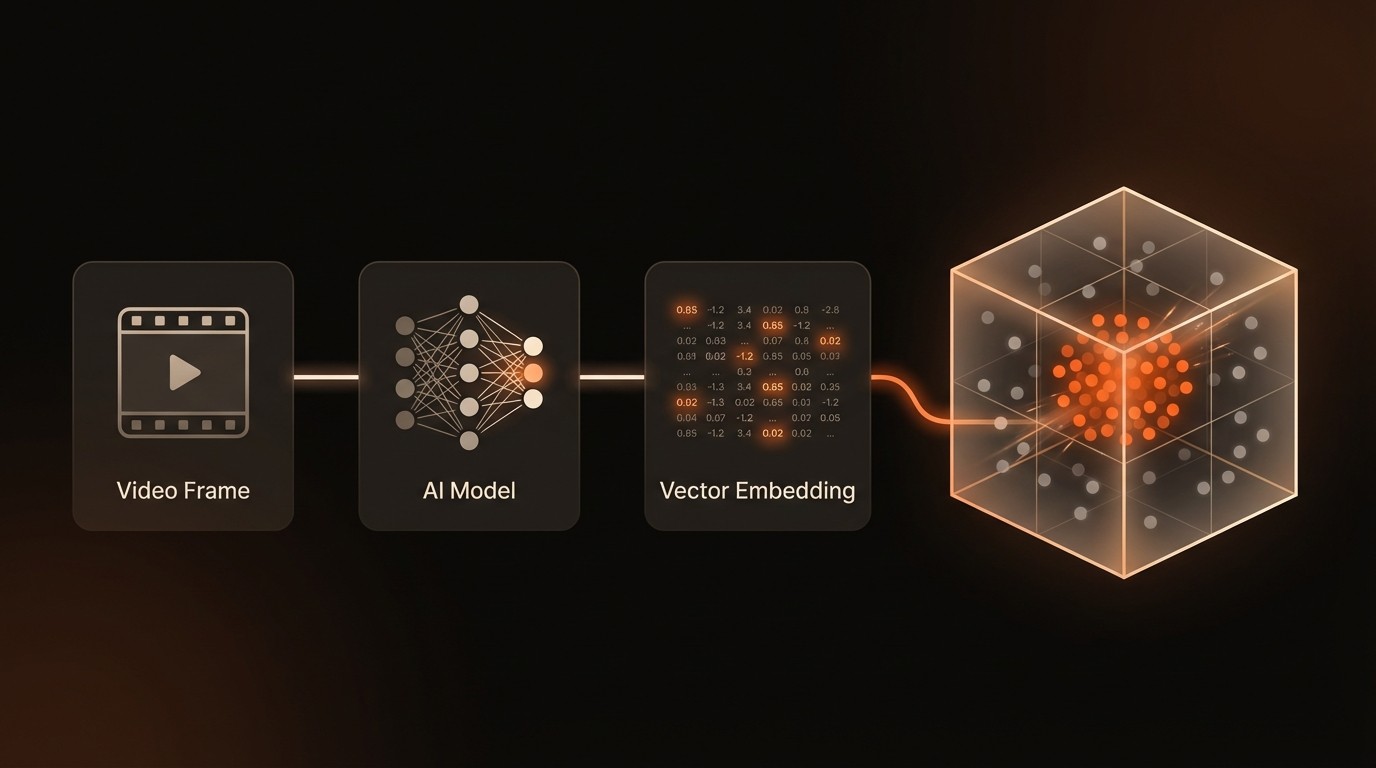
The Concept of Vector Space
Once we have these vector representations, we can think of them as points in a high-dimensional space. In this space, the distance between any two points corresponds to the semantic similarity of the original data they represent. Concepts that are closely related will have their vectors clustered together, while unrelated concepts will be far apart. The vector for "a person running" will be closer to the vector for "a marathon race" than it is to the vector for "a corporate boardroom meeting." The "distance" is typically calculated using mathematical formulas like Euclidean distance (the straight-line distance between two points) or Cosine Similarity (which measures the angle between two vectors). This spatial arrangement is the key that allows us to find conceptually similar items by searching for a vector's nearest neighbors in the space.
How Vector Databases Work
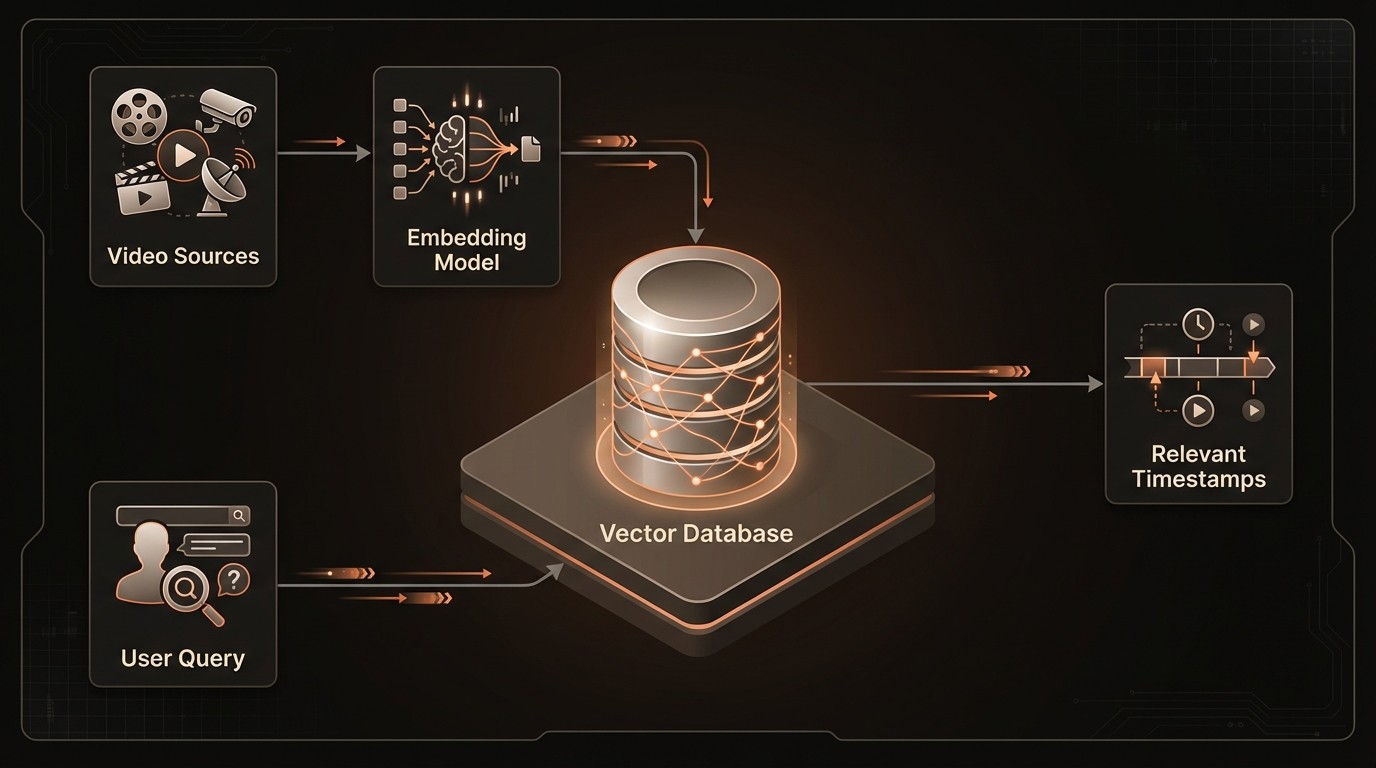
A VideoDB or vector database is a database system designed from the ground up to efficiently store, index, and query these high-dimensional vector embeddings. A traditional database would have to compare a query vector to every single vector in its dataset-a process called a brute-force or exhaustive search. This is incredibly slow and computationally expensive, making it impractical for real-world applications. Instead, vector databases use specialized indexing algorithms like HNSW (Hierarchical Navigable Small World) or IVF (Inverted File) to perform Approximate Nearest Neighbor (ANN) search. These algorithms build smart data structures, like a multi-layered graph, that allow the database to quickly navigate the vector space and find the closest matches without checking every single point. This is why, as Pinecone highlighted in 2021, vector databases can improve the speed of similarity searches by orders of magnitude.
Here is a conceptual representation of what these embeddings look like and how they relate:
This combination of AI-powered embeddings and purpose-built databases provides the technical foundation for a new generation of video applications, transforming video from a passive storage medium into an active, queryable source of intelligence.
Video Analytics by the Numbers
Here's what the data reveals about the rapidly growing landscape of video analysis and the technologies powering it:
Metric | Data Point | Implication |
|---|---|---|
Market Growth | The global video analytics market is projected to reach $21.9 billion by 2027. | This indicates massive investment and widespread adoption of AI-driven video analysis tools across industries. |
Search Performance | Vector databases can improve similarity search speed by orders of magnitude. | This performance leap enables real-time applications like live monitoring and instant content recommendation. |
Data Volume | Video comprises a significant portion of the world's data. | The sheer scale of video necessitates new, more efficient solutions for storage, indexing, and retrieval. |
Key Adoption Drivers | Organizations are increasingly using video analytics for security, surveillance, and business intelligence. | The technology has proven its value in mission-critical applications, driving demand for more advanced capabilities. |
Core Technology | Vector embeddings are the key to unlocking semantic search and understanding of video content. | The shift from metadata to semantic vectors represents a fundamental change in how we interact with video data. |
Building a Smarter Video Pipeline with Vector Databases
The theoretical advantages of vector databases translate into powerful, practical capabilities that can be integrated directly into video processing pipelines. By leveraging a VideoDB, organizations can move beyond basic storage and retrieval to build sophisticated, AI-driven workflows that extract deep, contextual insights from their video assets. These systems are not just faster; they enable entirely new ways of interacting with video content, from complex multi-modal queries to proactive, real-time event detection. The implementation of a VideoDB serves as the central nervous system for a modern video intelligence stack, coordinating the flow of vectorized data and enabling rapid, semantic-level queries that were previously impossible to execute at scale.
Ultra-Fast Similarity Search
The most fundamental capability of a VideoDB is its ability to perform similarity search at incredible speeds. This allows users to find relevant video content using a variety of inputs: a sample image, another video clip, or even a natural language text description. For example, a content moderator can upload an image containing prohibited content, and the system can instantly find all video frames across a massive library that are visually similar, flagging them for review. A film editor could take a 10-second clip and ask the system to find all other shots with a similar color palette, composition, and mood. This is made possible by the highly optimized ANN indexing within the VideoDB, which reduces search time from hours of manual labor or slow brute-force computation down to mere milliseconds.
Multi-Modal Search Capabilities
Modern video analysis isn't just about the pixels; it's about the interplay between visuals, audio, and text. A sophisticated VideoDB architecture can ingest and index vectors from multiple sources in a shared, multi-modal space. This means you can generate embeddings from video frames (visuals), spoken words from the audio track (transcript), and even ambient sounds (audio events). This unified index allows for incredibly powerful and specific queries. For instance, a market research firm could search a repository of customer interviews for moments where "a customer is smiling (visual) while the transcript contains the words 'product quality' (text) and their tone of voice is positive (audio)." This fusion of data modalities provides a holistic understanding of the video content that is far greater than the sum of its parts.
Real-Time Anomaly and Event Detection
For applications in security, industrial monitoring, and public safety, the ability to react in real-time is critical. By connecting a live video stream to an indexing pipeline, a VideoDB can power real-time event detection. Each incoming frame is converted into a vector and compared against a database of vectors representing "normal" activity. When a new frame produces a vector that is a significant outlier-meaning it's far away from the normal clusters in the vector space-the system can trigger an alert. In a manufacturing setting, this could mean detecting a piece of machinery that is vibrating abnormally. In a retail environment, it could identify a fall or a security breach. This proactive monitoring capability transforms video surveillance from a forensic tool used after an event into a real-time system for prevention and immediate response.
A conceptual API call for performing a semantic search with a modern VideoDB service might look like this:
Vector Databases in Action: From Media to Manufacturing
The application of vector databases to video data is not just a theoretical exercise; it's delivering tangible value across a diverse range of industries. By enabling efficient, semantic-level queries on visual data, this technology is solving long-standing challenges and creating new opportunities for automation, insight, and user engagement. From streamlining creative workflows to enhancing public safety, the real-world use cases demonstrate the transformative impact of treating video as a queryable, intelligent data source.
Media and Entertainment: Intelligent Content Discovery
Industry Context: Media organizations and production houses manage colossal archives containing millions of hours of raw footage, b-roll, and finished content. Locating specific clips for new projects has traditionally been a painstaking manual process, relying on inconsistent metadata and the institutional memory of archivists.
Implementation Scenario: A major broadcasting network implemented a VideoDB to index its entire historical archive. An AI pipeline continuously processes the footage, generating vector embeddings for scenes, objects, faces, and even abstract concepts like mood and tone. Producers and editors can now use a simple search interface to query the archive with natural language, such as "find dramatic drone shots of a coastline at sunset" or "show me all interviews with a specific politician from the last decade." The system returns a ranked list of relevant video segments in seconds.
Measurable Outcomes: This intelligent discovery platform has accelerated post-production workflows by an estimated 60%. The time required to assemble highlight reels, promotional materials, and documentary segments has been drastically reduced, allowing creative teams to focus on storytelling rather than tedious manual searches. It has also unlocked the value of their deep archive, surfacing forgotten footage that can be repurposed for new content.
Retail and Business Intelligence: Analyzing In-Store Customer Behavior
Industry Context: Brick-and-mortar retailers possess a wealth of data in their in-store security footage, but have historically struggled to extract actionable business intelligence from it. Understanding customer flow, product interaction, and sentiment is key to optimizing store layouts and improving sales.
Implementation Scenario: A large retail chain deployed a video analytics platform powered by a VideoDB across its flagship stores. The system processes camera feeds in real-time, vectorizing customer paths, dwell times in different aisles, and even anonymized sentiment analysis based on posture and expression. Store managers can query this data to ask questions like, "Which promotional display is attracting the most visual attention?" or "Identify areas of the store where customers appear confused or are looking for assistance."
Measurable Outcomes: By analyzing these patterns, the retailer identified several bottlenecks in their store layout and redesigned the customer flow. They also optimized product placement based on dwell time analysis, leading to a 15% increase in sales for high-margin products. The system also helped improve staffing efficiency by allocating employees to areas with high detected customer confusion.
Public Safety and Smart Cities: Proactive Incident Detection
Industry Context: Municipalities and law enforcement agencies are responsible for monitoring thousands of public cameras to ensure citizen safety. Manually monitoring all these feeds is impossible, meaning that most footage is only reviewed forensically after an incident has already occurred.
Implementation Scenario: A smart city initiative integrated a VideoDB into its central surveillance system. The platform indexes feeds from traffic and public space cameras in near real-time. The system is trained to recognize specific objects and events, allowing operators to perform similarity searches for a "blue sedan involved in a hit-and-run" or to set up automated alerts for events like a large crowd suddenly dispersing or a piece of luggage left unattended for an extended period.
Measurable Outcomes: The ability to perform rapid, cross-camera searches has reduced the time to identify vehicles or persons of interest from hours to minutes. The automated anomaly detection has led to a 40% faster response time for potential public safety incidents, as operators are alerted to unusual events as they happen, rather than discovering them during a later review.
Industry Voices on High-Dimensional Data
Industry leaders at the forefront of vector database technology emphasize its critical role in managing the next generation of AI-powered applications. Ram Sriharsha, VP of Engineering at Pinecone, highlighted in the Pinecone Blog that vector databases are essential for enabling the real-time similarity search and recommendation systems that are critical for modern video analysis applications. (2021) This underscores the need for speed and responsiveness when dealing with live or large-scale video feeds.
Similarly, the challenge of managing the complex data generated by AI models is a key focus. Lei Li, VP of Product at Zilliz, mentioned in the Zilliz Blog that vector databases provide efficient and scalable solutions specifically for managing and querying the high-dimensional vector embeddings extracted from video data. (2022) This points to the unique architectural requirements of vector data, which general-purpose databases are not equipped to handle efficiently, especially at the scale required for enterprise video platforms.
Your First Steps into Semantic Video Analysis
Adopting a vector-based approach to video analysis may seem complex, but breaking it down into a clear, step-by-step process can make it manageable. The key is to start with a well-defined problem and build out your capabilities iteratively. This roadmap provides a high-level guide for any team looking to move beyond metadata and unlock the semantic insights hidden within their video content.
Define Your Core Use Case: Before writing any code, clearly identify the business problem you want to solve. Is it to accelerate post-production, monitor for security events, or improve content recommendations? Starting with a specific, high-value goal will guide your technical decisions and ensure you deliver tangible results. Document the current process and its pain points to establish a baseline for measuring success.
Select Your Embedding Model: The quality of your search results depends heavily on the quality of your vector embeddings. You'll need to choose an AI model to convert your video frames and audio into vectors. For many use cases, pre-trained multimodal models like OpenAI's CLIP or Google's ViT are excellent starting points, as they can understand both images and text. Evaluate different models based on their performance on a sample of your own data to see which one best captures the nuances of your specific domain.
Set Up Your Vector Database: This is the core of your new pipeline. You have two main options: a managed, cloud-native service or a self-hosted open-source solution. Managed services like Pinecone, Zilliz Cloud, or a dedicated VideoDB platform can significantly accelerate development by handling infrastructure, scaling, and maintenance. Self-hosting solutions like Milvus or Weaviate offer more control but require more operational overhead. For most teams, starting with a managed service is the fastest path to a proof-of-concept.
Build Your Indexing Pipeline: This is the process that feeds your VideoDB. You need to build a data pipeline that can take a source video, break it down into its constituent parts (e.g., frames at one-second intervals, audio chunks, transcripts), run each part through your chosen embedding model, and then insert the resulting vectors into your vector database along with their associated metadata (e.g., video ID and timestamp). This can be built using workflow orchestration tools like Airflow or serverless functions.
Develop Your Search Application: With your data indexed, the final step is to build an application that can query it. This involves creating a user interface where a user can input a query (text, an image, etc.), converting that query into a vector using the same embedding model from your pipeline, and then sending that vector to your VideoDB's API to find the most similar vectors. The API will return a list of matching vector IDs and their similarity scores, which you can then use to retrieve and display the corresponding video clips.
Common Questions on Vector Databases for Video
Q: What's the difference between a vector database and a traditional database with a vector plugin?
A: A native vector database is purpose-built from the ground up for storing and querying high-dimensional vectors using specialized indexing algorithms like HNSW for maximum performance. A traditional database with a vector plugin bolts on vector search capabilities to an existing architecture that was designed for other data types. While plugins can be a good starting point, they often cannot match the low-latency performance, scalability, and feature set of a dedicated VideoDB for demanding, real-time applications.
Q: How are vector embeddings for video actually created?
A: Vector embeddings are created by a deep learning model. The process involves taking a video, sampling frames from it at a set interval (e.g., one frame per second), and feeding each frame into a pre-trained AI model like a vision transformer (ViT) or a multimodal model (like CLIP). The model processes the image and outputs a vector-a list of several hundred numbers-that represents the semantic content of that frame. The same can be done for audio segments or text from transcripts, creating a rich, multi-modal representation of the video.
Q: Is this technology expensive to implement?
A: The cost can vary significantly based on the scale of your data and your implementation choice. Using open-source models and self-hosting a database like Milvus can be cost-effective but requires significant engineering expertise. Managed cloud services for embedding models and vector databases (a VideoDB) operate on a pay-as-you-go model, which can be more expensive at massive scale but drastically lowers the upfront investment and operational overhead, making it more accessible for many teams to get started.
Q: Can a VideoDB search for audio events as well as visual ones?
A: Yes, absolutely. This is a key advantage of a multi-modal approach. Just as AI models can create embeddings for images, other models are trained to create embeddings for audio. You can process the audio track of a video to generate vectors for spoken words, music, or specific sound events like "glass breaking" or "sirens." By storing these audio vectors alongside the visual vectors in a VideoDB, you can perform searches that combine both sight and sound for highly specific results.
Q: What is Approximate Nearest Neighbor (ANN) search and why is it important?
A: Approximate Nearest Neighbor (ANN) search is the core technology that makes vector databases fast. Instead of performing an exact (or "brute-force") search that compares a query vector to every single vector in the database, ANN algorithms use clever indexing structures to quickly find vectors that are very likely to be the closest matches. This trades a tiny amount of accuracy for a massive gain in speed-often making searches hundreds or thousands of times faster. For video search, where finding a "good enough" match is usually sufficient, this trade-off is essential for enabling real-time performance.
Key Takeaways
Video data is a massive, unstructured resource whose value is often locked away due to the limitations of traditional keyword-based search.
Vector embeddings are the key to unlocking this value, translating complex visual and audio content into searchable mathematical representations.
A VideoDB or vector database provides the specialized, high-speed infrastructure required for real-time similarity search, performing orders of magnitude faster than traditional methods.
Real-world applications are already driving value in media, retail, and public safety, contributing to a video analytics market projected to hit $21.9 billion by 2027.
A successful implementation starts with a clear use case and involves a pipeline for creating embeddings, indexing them in a VideoDB, and building an application to query them.









