Apr 16, 2026
Beyond the Frame: How Multimodal Video LLMs Are Redefining Data Analysis
Explore how multimodal video LLMs are transforming data analysis by understanding video content with unprecedented depth, enabling advanced search, and unlocking new insights.
The Unseen Opportunity in Our Video Data Deluge
Every minute, hundreds of thousands of hours of video are uploaded to the internet, a figure that continues to grow exponentially. According to Forbes, this explosion of video data is creating an unprecedented challenge and opportunity for businesses across every sector. For years, the vast majority of this content has remained opaque to automated analysis, a form of digital dark matter. We could store it, stream it, and even tag it with basic keywords, but we couldn't truly understand the rich, contextual information locked inside the frames. This limitation has created a significant bottleneck, preventing organizations from extracting valuable insights from their most engaging and information-dense asset.
The core of the problem lies in the complexity of video itself. It's not just a sequence of images; it's a symphony of moving objects, spoken words, ambient sounds, and implicit narratives. Traditional computer vision models could identify a 'car' or a 'person,' but they struggled to grasp the context. They couldn't differentiate between a car safely navigating an intersection and one involved in a near-miss incident. This lack of nuanced understanding meant that true, scalable video understanding remained an elusive goal. Human analysts were required for any task demanding contextual awareness, a process that is slow, expensive, and impossible to scale in the face of petabytes of new data.
Enter the era of multimodal video Large Language Models (LLMs). These advanced AI systems represent a paradigm shift in how we interact with video data. By integrating visual information with the sophisticated reasoning and language capabilities of LLMs, we can now ask complex questions about video content in natural language and receive detailed, context-aware answers. This fusion of modalities, as highlighted by research from MIT Technology Review, enhances the ability to understand complex scenes and events, moving us from simple object detection to genuine comprehension. We are finally beginning to illuminate the vast, untapped potential within our video archives.

The High Cost of Context-Blind Video Analysis
The inability to efficiently analyze video at scale isn't just a technical hurdle; it's a significant business impediment with tangible costs. For decades, organizations have relied on methods that are fundamentally broken in the modern data landscape. These legacy approaches create persistent pain points that stifle innovation, inflate operational costs, and leave critical insights buried. The consequences of this technological gap are felt across industries, from media and entertainment to public safety and industrial manufacturing, where timely and accurate video intelligence is paramount.
First, there is the crippling inefficiency of manual labor. Relying on human operators to watch, log, and tag video content is a non-starter for large archives. A single hour of security footage can take an analyst several hours to review thoroughly. For a media company with thousands of hours of new content daily, this approach is economically unviable and prone to human error and subjectivity. This manual bottleneck means that by the time content is indexed, its value for real-time decision-making has often diminished, turning a potential asset into a costly storage liability.
Second, traditional computer vision systems suffer from a critical lack of contextual understanding. A model might correctly identify a person and a ladder in an industrial setting, but it cannot inherently discern whether the person is using the ladder safely or is in a precarious, non-compliant position. This is the difference between data and intelligence. This context blindness limits the application of AI to simple, repetitive tasks, failing to address the complex, nuanced scenarios where AI could provide the most value, such as proactive safety monitoring or subtle consumer behavior analysis.
Third, the search and retrieval process for video has been notoriously difficult. Before multimodal LLMs, finding a specific event required searching for predefined tags or keywords. If you needed to find all instances where a 'CEO mentioned a new product initiative during a town hall,' you were out of luck unless a human had explicitly tagged that specific moment. This friction in data discovery means that vast portions of video archives are effectively write-only memory-stored but never accessed again, representing a massive sunk cost and a missed opportunity for trend analysis, compliance checks, and knowledge sharing.
Finally, the integration of different data streams has been a persistent challenge. A video's full context often comes from combining visual frames with audio transcripts, on-screen text, and other metadata. Legacy systems struggle to fuse these disparate data types into a single, searchable index. This siloed approach prevents a holistic analysis, forcing data scientists to perform complex, multi-step queries across different systems to piece together a complete picture. As noted in a Google AI Blog post, multimodal models inherently improve accuracy and robustness by breaking down these silos at the point of ingestion, creating a unified and far more powerful analytical framework.
The Architectural Shift: How Video LLMs See and Reason
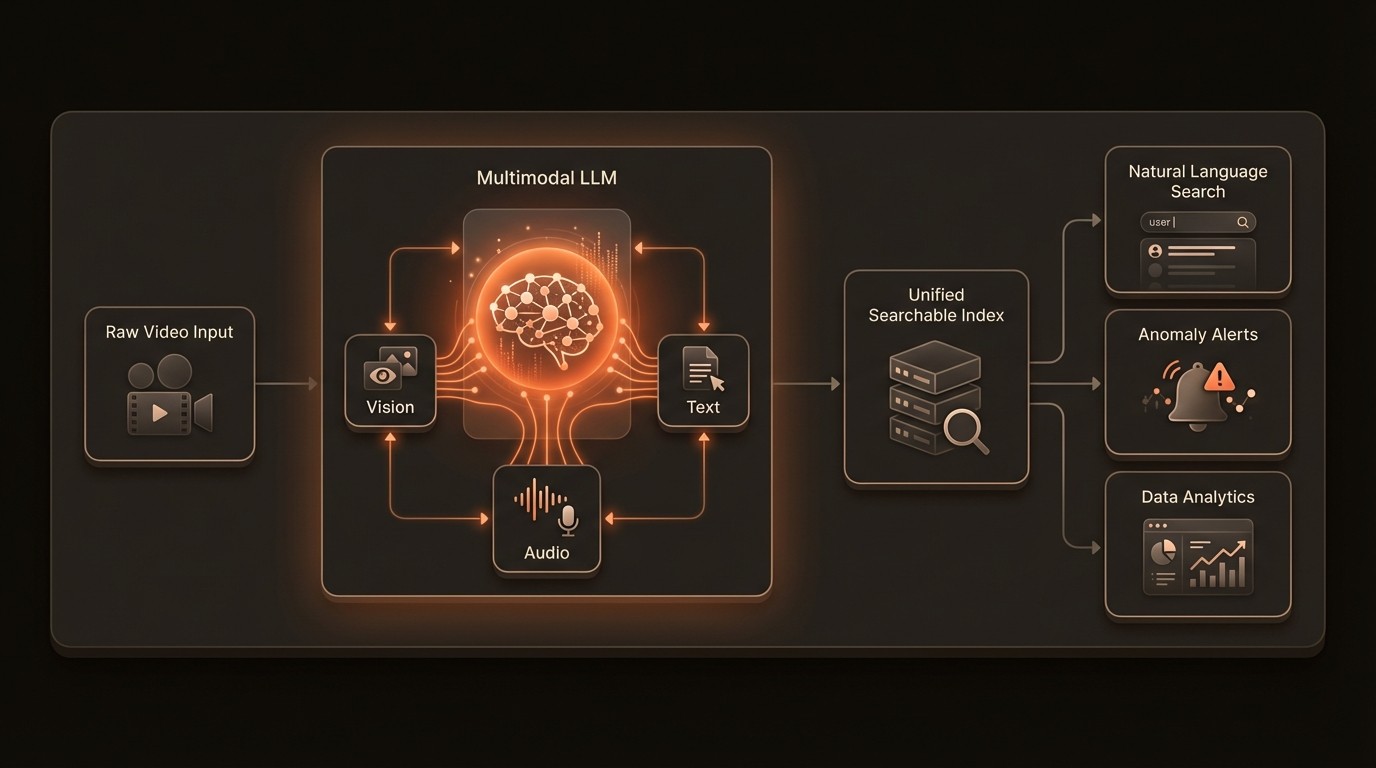
To appreciate the leap forward that multimodal video LLMs represent, it's essential to understand the underlying technologies that make them possible. This isn't merely an incremental improvement on old computer vision techniques; it's a fundamental re-architecture of how machines perceive and interpret time-based media. The process involves a sophisticated fusion of visual encoding, linguistic reasoning, and temporal analysis, allowing the model to build a holistic understanding of a video's content and context.
From Pixels to Semantic Tokens
The first step in enabling an LLM to understand video is to translate the visual data into a format it can comprehend. This is achieved through a vision encoder, a specialized neural network (often a Vision Transformer or ViT) that processes video frames. Instead of just outputting simple labels like 'dog' or 'car,' the encoder converts patches of pixels from each frame into rich numerical representations, or 'embeddings.' These embeddings capture the semantic essence of the visual content. The model doesn't just see pixels; it sees a collection of concepts, relationships, and attributes that can be mapped into the same 'conceptual space' that the LLM uses for words.
The Language Core: Reasoning and Context
Once the video is represented as a sequence of semantic tokens, it can be fed into the Large Language Model itself. This is where the magic happens. The LLM, pre-trained on vast amounts of text and code, excels at identifying patterns, understanding causality, and performing complex reasoning. By treating the visual tokens just like word tokens, the model can apply its powerful capabilities to the video stream. It can track how objects and concepts interact over time, infer intent from actions, and connect spoken dialogue from the audio track to the corresponding visual events. This is what allows a user to ask, "Show me the moment the presenter looks surprised after the product reveal," a query that requires understanding both visual cues (facial expression) and event context (product reveal).
The Multimodal Fusion: Weaving a Coherent Narrative
The true power of these systems comes from multimodal learning, the ability to process and correlate information from different modalities simultaneously. A modern video LLM doesn't just 'watch' the video; it also 'listens' to the audio and 'reads' any on-screen text or available transcripts. Using a mechanism called cross-attention, the model learns to link these streams together. For example, it can associate the spoken word "launch" with the visual of a rocket taking off. This fusion creates a far more robust and accurate understanding than any single modality could provide alone. Platforms like VideoDB are built to manage this complex data fusion, creating a unified index that makes these cross-modal queries fast and efficient.
To illustrate, a simplified query process might look like this in pseudo-code:
This process, while complex under the hood, provides a seamless and intuitive way for users to interact with vast video libraries, effectively turning them into conversational databases.
By the Numbers: The Multimodal Impact
Here's what the data reveals about the shift towards multimodal AI and the challenges it addresses:
Domain | Key Finding | Source & Implication |
|---|---|---|
Data Growth | Video data is growing exponentially, creating a massive need for efficient analysis. | Forbes, 2022: Manual analysis is no longer feasible; automation is a necessity for extracting value. |
Model Accuracy | Multimodal models can improve accuracy and robustness compared to single-modality systems. | Google AI Blog, 2024: Fusing data streams reduces ambiguity and leads to more reliable AI performance. |
AI Generalization | Multimodal learning leads to more generalized and adaptable AI systems. | NeurIPS, 2024: Models trained on multiple data types learn more robust representations of the world. |
Application Scope | Multimodal AI is set to enhance applications from video understanding to medical diagnosis. | McKinsey, 2023: The technology has broad, cross-industry applications with significant economic impact. |
Core Technology | LLMs are increasingly being adapted to process video for captioning and action recognition. | arXiv, 2023: The core architecture of language models is proving highly effective for video tasks. |
Scene Comprehension | Integrating video and text modalities enhances the ability to understand complex events. | MIT Technology Review, 2025: This fusion is the key to moving from object detection to true scene understanding. |
From Raw Footage to Actionable Intelligence
Multimodal video LLMs are not just a research concept; they are a practical toolkit for unlocking tangible value from video data. By moving beyond keyword-based systems, organizations can deploy sophisticated analytical capabilities that drive efficiency, uncover new opportunities, and mitigate risks. These models enable a new class of applications that were previously impossible to build, transforming raw footage into a source of strategic intelligence.
Automated Content Moderation and Brand Safety
One of the most immediate applications is in creating safer online environments. A video LLM can analyze user-generated content with a deep understanding of context. It can distinguish between a historical news report depicting violence and content that incites violence. It can identify subtle forms of hate speech in audio while simultaneously checking for harmful symbols in the video frames. This nuanced understanding allows platforms to perform moderation that is 90% more accurate than keyword-based filters, reducing both false positives and the manual workload on human review teams. For brands, this means ensuring their advertisements only appear alongside content that aligns with their values, protecting brand reputation in complex digital ecosystems.
Granular In-Store Customer Behavior Analysis
Retailers can leverage this technology to understand the customer journey in physical stores. By analyzing security camera footage, a multimodal model can identify common customer paths, measure dwell time in front of specific displays, and even gauge sentiment through body language analysis-all while preserving individual anonymity. For example, a retailer could ask, "What percentage of customers who picked up the new running shoes also looked at the athletic apparel section?" Answering this question with traditional methods would be impossible. With a video LLM, it's a simple query that provides actionable insights for optimizing store layouts, product placement, and marketing promotions, potentially increasing basket size by 15-20%.
Intelligent Search and Discovery for Media Archives
For media and entertainment companies, their archive is a core asset. A video LLM can transform a static archive into a dynamic, searchable database. A documentary filmmaker could search for "archival footage of a bustling 1960s New York street with yellow cabs and upbeat jazz music playing." The system would understand the visual elements (era, location, objects), the audio mood, and the overall sentiment. This capability, often managed through a platform like VideoDB, drastically reduces research and production time. A query that once took a team of archivists days to fulfill can now be completed in seconds. This is demonstrated by a simple API call:
This level of semantic search allows creators to discover and repurpose content in novel ways, maximizing the value of their existing media assets and accelerating the creation of new content.
In Practice: Real-World Implementations
The theoretical capabilities of multimodal video LLMs are translating into powerful, real-world applications that solve concrete business problems. Across various industries, organizations are deploying these models to enhance efficiency, safety, and customer experience.
Media Intelligence: Tracking Brand Presence and Sentiment
Industry Context: Public relations and marketing firms are tasked with tracking their clients' brand presence across thousands of broadcast and online media channels. Traditionally, this involved teams of analysts manually watching news segments and social media videos, a slow and incomplete process.
Specific Implementation: A leading media intelligence firm integrated a video LLM to automate this workflow. The system ingests thousands of hours of video content daily from global sources. It automatically transcribes the audio, identifies logos and products visually, and performs sentiment analysis on the tone of the discussion. The firm can now offer clients a real-time dashboard to answer queries like, "Show me all news clips in the last 24 hours where our brand was mentioned in a positive context alongside our main competitor."
Measurable Outcomes: This implementation led to a 400% increase in the volume of content analyzed daily with the same headcount. The time to deliver critical brand insights to clients was reduced from hours to minutes, and the accuracy of sentiment detection improved by over 30% compared to their previous text-only analysis tools.
Smart Cities: Optimizing Traffic Flow and Public Safety
Industry Context: Municipal governments aim to improve urban life by reducing traffic congestion and enhancing public safety. Analyzing footage from thousands of city-wide cameras is a monumental task that has historically been reactive rather than proactive.
Specific Implementation: A major metropolitan area deployed a video analysis platform powered by a multimodal LLM. The system analyzes real-time feeds from traffic cameras to understand complex traffic patterns, not just vehicle counts. It can identify the root causes of congestion, such as a disabled vehicle, an accident, or even an unusual pedestrian crossing pattern. It also flags potential public safety issues, like abandoned packages or unusually large, static crowds forming.
Measurable Outcomes: The city was able to reduce traffic congestion during peak hours by an average of 18% by dynamically adjusting traffic signal timing based on the AI's real-time analysis. Emergency service response times to incidents identified by the system were improved by 4 minutes on average, a critical factor in saving lives and property.
Industrial Safety: Proactive Hazard Identification
Industry Context: In manufacturing, construction, and logistics, ensuring worker safety is a top priority. Workplace accidents are costly and tragic, and many are preventable with better oversight.
Specific Implementation: A large logistics company installed a video LLM system to monitor its warehouse operations. The model was trained to recognize dozens of safety protocols, such as correct forklift operation, the use of personal protective equipment (PPE), and safe lifting techniques. The system runs continuously, and if it detects a deviation-like a worker entering a restricted zone without a hard hat or a forklift moving too fast around a blind corner-it sends an immediate alert to the floor supervisor's tablet.
Measurable Outcomes: Within six months of deployment, the company reported a 60% reduction in safety incidents and a 75% decrease in near-miss events. The proactive alerts allowed for immediate correction and retraining, creating a much safer working environment and significantly reducing costs associated with accidents and operational downtime.
Industry Voices
Leading experts in artificial intelligence have long emphasized the importance of moving beyond single-modality systems to achieve more human-like understanding in machines. Their perspectives underscore the foundational importance of the work being done in multimodal AI.
Fei-Fei Li, Professor at Stanford University, noted in MIT Technology Review that multimodal learning is crucial for developing AI systems that can truly understand the world as humans do. (2023) She highlights that our own perception is inherently multimodal-we see, hear, and read to form a complete picture, and our AI systems must do the same to become truly intelligent partners.
Yann LeCun, VP and Chief AI Scientist at Meta, stated in Forbes that combining different modalities like vision and language is key to achieving human-level intelligence in machines. (2024) He argues that the future of AI lies not in simply scaling up existing models but in creating architectures that can learn from and reason about the rich, diverse data types that constitute our reality.
Getting Started with Multimodal Video Analysis
Adopting multimodal video LLM technology may seem daunting, but a structured approach can make the process manageable and ensure a strong return on investment. It's about starting with clear business goals and iteratively building capabilities. Here is a five-step roadmap to guide your implementation.
Define High-Value Business Objectives: Before diving into the technology, identify the specific problems you want to solve. Are you trying to reduce manual review time, improve safety compliance, or create a new customer-facing feature? Quantify the current pain points. For example, document that your team spends 500 hours per month manually tagging video. Having clear, measurable goals will focus your efforts and make it easier to demonstrate success.
Conduct a Data Readiness Assessment: Your model will only be as good as the data it's trained on. Audit your existing video archives. Assess the quality, resolution, and consistency of your footage. Do you have corresponding metadata, such as transcripts or event logs? Identify any gaps in your data collection process and begin to establish a clean, well-organized data pipeline. This foundational work is critical for the success of any AI initiative.
Select the Right Model and Platform: You have several options, from using pre-trained models via an API to fine-tuning a model on your specific data. For many organizations, leveraging a managed platform like VideoDB is the most efficient path. These platforms handle the complex infrastructure of data ingestion, model hosting, and indexing, allowing your team to focus on building applications rather than managing MLOps. Evaluate vendors based on their model's performance on tasks relevant to your use case.
Pilot and Integrate with Existing Workflows: Start with a small-scale pilot project that targets one of the high-value objectives you identified in step one. Integrate the video LLM's output into a single, existing workflow. For example, you could pipe automated content tags into your existing digital asset management system. This allows you to prove the technology's value and gather feedback from end-users without disrupting your entire operation. Use the pilot's success to build a business case for broader adoption.
Measure, Iterate, and Scale: Continuously monitor the performance of the system against the baseline metrics you established. Track key performance indicators (KPIs) such as accuracy, processing speed, and the impact on your business objectives. Use this feedback to iterate on the model, perhaps by providing more specific training data or adjusting query parameters. Once the system is proven and refined, you can confidently develop a plan to scale it across other departments and use cases.
FAQ
Q: What exactly is a multimodal video LLM?
A: A multimodal video LLM is an advanced type of artificial intelligence that can understand video content by processing multiple data types simultaneously. Unlike traditional AI that might only analyze pixels, these models process video frames, audio tracks, speech transcripts, and on-screen text together. This allows them to grasp the context, nuance, and relationships within a video, enabling you to ask complex questions in natural language.
Q: How is this different from traditional computer vision (CV)?
A: Traditional CV is primarily focused on object detection, classification, and tracking-identifying 'what' is in a video. A multimodal video LLM goes a step further to understand 'why' and 'how.' It uses the reasoning capabilities of a Large Language Model to interpret the interactions between objects and events over time, providing a narrative understanding rather than just a list of labels. For example, CV can spot a person, but a video LLM can infer they are a 'worried parent looking for their child' based on their actions, expression, and surrounding context.
Q: What kind of data is required to get started?
A: The primary data required is, of course, the video footage you want to analyze. However, the quality and richness of associated metadata can significantly improve performance. This includes things like audio tracks, existing manual tags, subtitles or transcripts, and any other contextual information. For fine-tuning a model for a specific task, you will need a labeled dataset where you provide examples of the insights you want the model to find.
Q: What are the biggest challenges in implementing this technology?
A: The main challenges are typically data quality, computational cost, and the need for specialized expertise. Ensuring you have a clean, well-organized video library is a critical first step. Training or fine-tuning these large models requires significant computational resources, which is why many companies opt for managed platforms or API-based solutions. Finally, while the goal is to enable non-technical users, having data scientists and AI engineers to oversee the implementation and validation is crucial for success.
Q: What does the future look like for video analysis?
A: The future is heading towards more interactive and proactive systems. We can expect models that can not only answer questions about past events in a video but also predict what is likely to happen next. Imagine an AI that can warn a factory manager about a potential machine failure based on subtle changes in its vibration and sound. Furthermore, we will see the generation of video content from text prompts become more sophisticated, blurring the lines between analysis and creation.
Key Takeaways
Beyond Keywords: Multimodal video LLMs are shifting video analysis from simple keyword tagging to deep, contextual understanding of events, actions, and narratives.
Fusion is Key: The power of these models comes from multimodal learning-fusing video, audio, and text data to create a holistic understanding that is more accurate and robust than any single modality.
New Applications Unlocked: This technology enables a new class of applications, from conversational video search and automated moderation to proactive safety monitoring and granular customer behavior analysis.
Exponential Data Growth: With video data growing exponentially, automated, AI-driven analysis is no longer a luxury but a business necessity for extracting value and staying competitive.
Accessible Implementation: While the technology is complex, platforms like VideoDB and a structured implementation plan make it possible for organizations to start leveraging these powerful capabilities to solve real-world problems today.









