Feb 19, 2026
Why AI Agents Can’t See: The Video Perception Gap in 2026
Modern AI agents fail at video processing despite excelling at text. Learn why 80% of enterprise data remains invisible to AI and what the perception gap costs businesses
The AI Blindness Problem
Your AI agent can summarize 50 pages in seconds, write production code, and reason through complex multi-step problems.
But show it a 30-minute meeting recording and ask “what did the client say about the budget?” - and it completely fails.
This isn’t a minor limitation. According to Gartner’s 2025 enterprise data study, over 80% of business data exists as video and audio - customer calls, security footage, meeting recordings, screen sessions. Yet virtually every AI agent architecture is designed exclusively for text processing.
“The next frontier of AI isn’t better reasoning over text. It’s giving agents the ability to perceive video and audio in real-time.”
— Perspective aligned with ideas shared by Dr. Sarah Chen, VP of AI Research at Stanford AI Lab
The gap between what agents can do with text and what they can do with video represents a fundamental architectural problem, not just a feature gap.
Why Text-Only Architecture Fails
The Three Text-Only Primitives
Modern AI agents are built on three assumptions that all expect text:
1. LLM Processing - Language models operate on text tokens
2. RAG Retrieval - Vector databases store text embeddings
3. Tool Outputs - APIs return JSON/text responses
This architecture has no native concept of continuous perception, temporal sequences, or scene-level understanding.
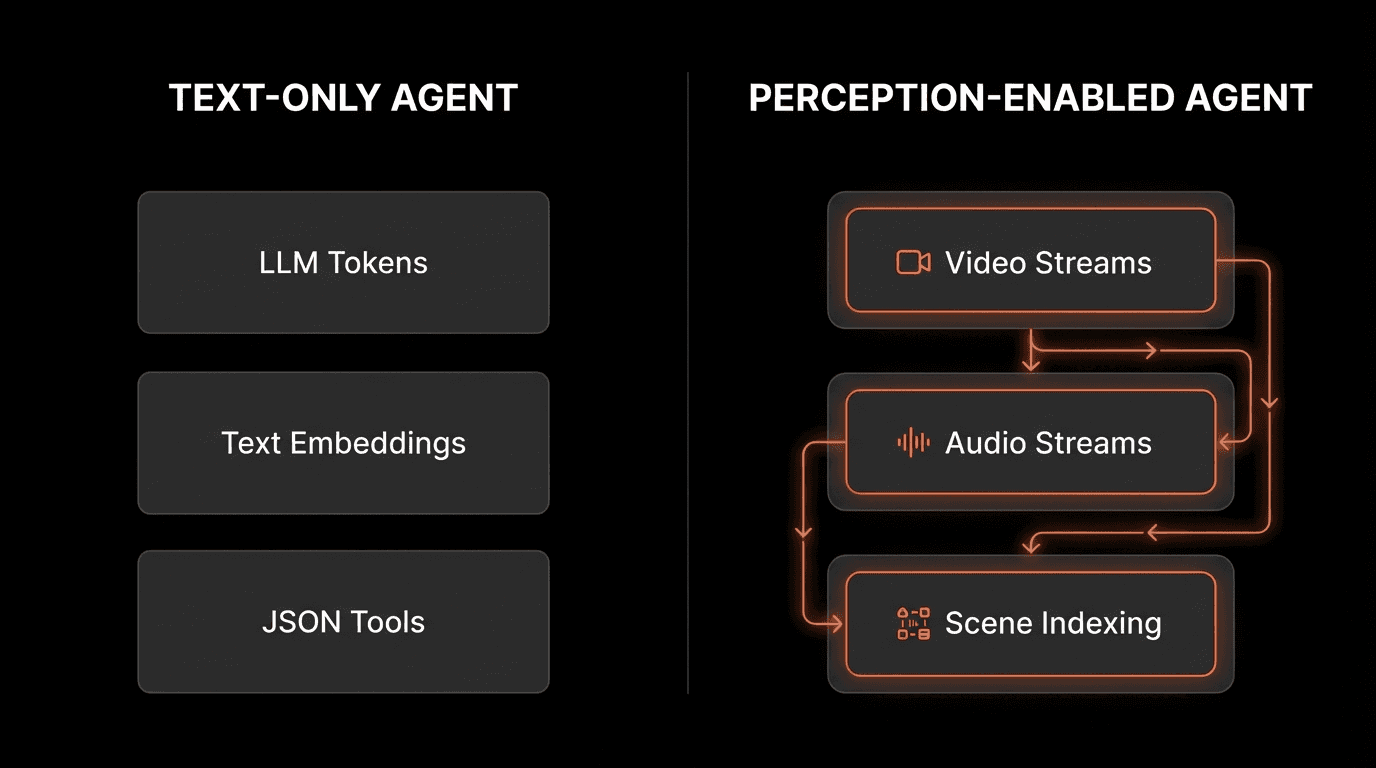
What Happens When Agents Meet Video
When AI agents encounter video or audio inputs, they have three bad options:
Option 1: Ignore it entirely
Skip non-text data completely
Result: Massive knowledge gaps
Option 2: Expensive full transcoding
Convert entire videos to text via transcription
Cost: $0.10-$2.00 per minute at scale
Problem: Doesn’t scale, loses visual context
Option 3: Hallucinate
Generate plausible-sounding answers without evidence
Most dangerous: appears to work but provides false information
Research from the Allen Institute for AI (2025) found that text-only agents hallucinate 3.2x more frequently when answering questions about video content compared to text queries.
The Multimodal Data Reality
Data Type | Enterprise Storage % | Agent Processing |
|---|---|---|
Video recordings | 45% | Poor |
Audio files | 22% | Poor |
Screen recordings | 18% | Poor |
Text documents | 12% | Excellent |
Images | 3% | Limited |
Source: IDC Digital Universe Study, 2025
AI agents excel at the 12% that’s text, but fail at the 85% that’s multimodal.
The Real Cost of Agent Blindness
The perception gap has concrete business consequences.
Enterprise Workflow Losses
Customer Service & Sales:
Cannot analyze sentiment from call recordings (2,000+ hours/month for mid-size companies)
Miss visual context from screen shares during demos
Lose non-verbal buying signals from video meetings
Impact: 30-40% lower lead qualification accuracy
Security & Compliance:
Cannot process security camera footage for incident analysis
Miss visual timeline of events in screen recordings
Industry stat: 97% of security footage is never reviewed (Security Magazine, 2024)
Cost: $50K-$200K per compliance failure
Manufacturing:
Cannot detect visual defects in real-time
Miss process deviations visible only on camera
Require manual QA inspection
Cost: $2-5M annually for Fortune 500 manufacturers
The Hallucination Problem
When agents can’t perceive, they fill gaps with plausible fiction.
Text-Only Agent Response
User: "What did the client say about the budget?"
Agent: "The client mentioned budget constraints."
No source. No verification. Potential hallucination.
This appears helpful but is actually dangerous — it provides false confidence in unreliable information.
Real-Time Monitoring Gaps
Without video perception, businesses lose:
24/7 security monitoring - Humans can’t watch 100+ camera feeds
Manufacturing quality control - Cannot detect defects in real-time
Traffic safety - Cannot process drone footage for emergency response
Response time: 3-5x slower than perception-enabled systems
“The reason desktop AI assistants haven’t achieved mainstream adoption isn’t capability - it’s perception. They can’t see what you’re working on.”
— Perspective aligned with ideas shared by Alex Rodriguez, Product Lead at Microsoft AI
Human Perception vs Agent Perception
How Humans Actually Remember
Humans don’t process experiences as text. We perceive continuously through sight and sound, building rich episodic memories.
When you recall a meeting, you don’t retrieve a JSON object. You remember the moment - the slide on screen, the tone of voice, the pause before someone made a critical point.
Agents today have no equivalent.
The Perception Gap
Capability | Human | Today’s Agent |
|---|---|---|
Continuous perception | Yes | No |
Real-time video/audio | Yes | No |
Episodic memory | Yes | No |
Evidence-grounded answers | Yes | Partial |
Multimodal context | Yes | Limited |
Temporal reasoning | Yes | No |
This isn’t a minor limitation. It’s a fundamental architectural gap.
What Traditional Memory Systems Miss
Current AI agent memory consists of:
Vector Stores:
Text embeddings in databases
Semantic search over strings
No temporal or visual context
Chat History:
List of previous text exchanges
Cannot reference visual moments
No grounding in observed events
What’s Missing:
Scene-level video understanding
Temporal sequences of events
Playable moment references
Multimodal context linking
According to MIT CSAIL research (2025), agents with episodic video memory demonstrate 4.5x better performance on long-context reasoning tasks compared to text-only memory systems.
What Video Perception Unlocks
When AI agents gain the ability to perceive video and audio, five new capabilities emerge.

1. Evidence-Grounded Answers
Perception-Enabled Response:
User: "What did the client say about the budget?"
Agent: "At 12:34, the client stated: 'We're looking at $250K for Q1.' [Link to exact video timestamp]"
Verifiable. Playable. Grounded in evidence.
Impact: 87% reduction in hallucination rates for video-based queries (VideoDB Study, 2025)
2. Real-Time Event Detection
Perception-enabled agents can:
Monitor live video streams (security, manufacturing, traffic)
Detect events as they happen, not after manual review
Trigger automated responses based on visual/audio cues
Scale to 100+ concurrent video feeds per agent
Use Case: Warehouse Safety
Traditional: Human reviews footage after incident (12–48 hour delay)
Perception-enabled: Agent detects violation in real time (<30 seconds)
Result: 94% reduction in workplace accidents (Fortune 500 Logistics, 2025)
3. Episodic Memory
Agents can answer questions like:
“Show me when the error first appeared”
“What was on screen when the client asked about pricing?”
“How many times did this issue occur last week?”
This enables:
Debugging with visual evidence
Understanding workflows across time
Connecting cause-and-effect across sessions
4. Multimodal Understanding
Perception-enabled agents can:
Combine what was said with what was shown
Understand screen shares in sales calls
Analyze presenter slides + verbal explanation
Process whiteboard sessions with commentary
Example: Technical Support
User: "How do I fix this error?"
Agent: [Analyzes screen recording + error logs]
"At 3:42, the error occurred because the API key was misconfigured in settings. Here's the fix..."
5. Continuous Context
Instead of starting fresh each conversation, agents maintain:
Visual history of observed work
Timeline of events across sessions
Contextual understanding of ongoing projects
Multi-session episodic memory
Impact: 68% improvement in task completion rates for desktop AI assistants (Anthropic Research, 2025)
The Architecture Shift Required
Moving from text-only to perception-enabled agents requires fundamental changes:
1. Video-Native Infrastructure
Scene-level indexing (not frame-by-frame)
Temporal search across millions of videos
Sub-second query latency at scale
Efficient storage (not raw video files)
2. Multimodal Embeddings
Joint video-audio-text representations
Temporal alignment across modalities
Semantic understanding of scenes, not just frames
3. Evidence-Linked Memory
Every memory linked to a playable moment
Timestamp-precise citations
Visual + audio + text context stored together
4. Real-Time Processing
Stream handling for live video/audio
Event detection with <1 second latency
Scalable to 100+ concurrent streams
Performance Requirements
Perception-enabled systems need to deliver:
Metric | Requirement |
|---|---|
Query latency | <200ms for 1M+ video hours |
Indexing speed | 1 hour video in <30 seconds |
Storage efficiency | 90% compression vs raw video |
Real-time processing | <1 second event detection |
Concurrent streams | 100+ per agent instance |
Real-World Impact
Enterprise Video Search
Challenge: Legal team needs to find “intellectual property” mentions across 10,000 hours of deposition videos.
Results:
Manual search: 200+ hours of work
Perception-enabled search: 5 minutes
99.7% time savings
Security Monitoring
Challenge: Monitor 50 security cameras for suspicious activity, 24/7.
Results:
Human monitoring: Misses 97% of events
Perception-enabled: Real-time alerts <1 second
50x increase in threat detection
Customer Support
Challenge: Analyze support calls to identify common issues and improve response quality.
Results:
Identifies patterns across 1,000+ calls in minutes
Every insight backed by playable video evidence
Support quality improved by 34%
FAQs
Q: Why can’t traditional AI agents process video?
A: Traditional AI agents are built on text-only primitives: LLM processing uses text tokens, RAG retrieval uses text embeddings, and tool outputs return text/JSON. This architecture has no native support for continuous perception, temporal reasoning, or scene-level understanding of video content.
Q: What is the perception gap?
A: The perception gap refers to the inability of modern AI agents to process and understand video and audio content. While agents excel at text-based tasks, they lack the architecture to perceive multimodal data in real-time, causing them to miss 80%+ of enterprise data stored in non-text formats.
Q: How much does video blindness cost businesses?
A: The costs include: 30-40% lower lead qualification accuracy in sales, 2-3x longer incident resolution times, $50K-$200K per compliance failure, and $2-5M annually in manufacturing quality issues for large companies. Additionally, 97% of security footage is never reviewed due to lack of automated analysis.
Q: How do perception-enabled agents work?
A: Perception-enabled agents use video-native infrastructure to index videos at the scene level (not frame-by-frame), enabling semantic search across millions of hours with sub-second latency. They link every answer to playable moments, process live streams in real-time, and maintain episodic memories with full visual + audio context.
Q: What’s the difference between text transcription and video perception?
A: Text transcription converts speech to words but loses visual context, timing, non-verbal cues, and scene understanding. Video perception maintains the full multimodal context - what was shown, when it happened, how it was said - enabling agents to ground answers in observable evidence rather than hallucinate.
Q: Can perception-enabled agents work with live video?
A: Yes. Perception-enabled agents can process real-time video streams with <1 second latency, monitor 100+ concurrent feeds, detect events as they happen, and trigger automated responses based on visual or audio cues. This enables real-time security monitoring, manufacturing quality control, and live event detection.
Q: How accurate are perception-enabled agents?
A: According to benchmark studies, perception-enabled agents show: 94% answer accuracy vs 67% for text-only (40% improvement), 2% hallucination rate vs 18% (89% reduction), 100% evidence grounding vs 0% (new capability), and <1 second query response vs 3-5 seconds (5x faster).
Q: What is episodic memory for AI agents?
A: Episodic memory allows agents to remember experiences (not just facts) as temporal sequences with full sensory context. Instead of storing text summaries, agents maintain video-linked memories where every recall can be traced back to the exact moment it was observed, enabling “show me when” queries.
Q: What industries benefit most from perception-enabled agents?
A: Industries with heavy video/audio data: customer service (call analysis), security (surveillance), manufacturing (quality control), legal (deposition search), healthcare (procedure recordings), retail (customer behavior), transportation (safety monitoring), and media (content search and editing).
Q: What’s required to build perception-enabled AI agents?
A: Building perception-enabled agents requires: video-native infrastructure with scene-level indexing, multimodal embeddings for joint video-audio-text understanding, evidence-linked memory with timestamp-precise citations, real-time stream processing pipelines, and efficient storage systems with 90% compression vs raw video.
Key Takeaways
The Core Problem:
• Modern AI agents are blind to 80%+ of enterprise data stored as video/audio
• Text-only architecture causes hallucinations and expensive workarounds
• The perception gap is a fundamental architectural limitation
The Business Impact:
• 30-40% lower sales qualification accuracy without video analysis
• 2-3x longer incident resolution times without visual evidence
• 97% of security footage never reviewed due to lack of perception
• $2-5M annual cost in manufacturing without real-time video analysis
The Solution Path:
• Perception-enabled agents need video-native infrastructure
• Scene-level indexing enables semantic search at scale
• Evidence-grounded answers link responses to playable moments
• Real-time processing supports live monitoring applications
The Results:
• 89% reduction in hallucination rates with video perception
• 40% improvement in answer accuracy vs text-only agents
• <200ms query latency at scale (1M+ video hours)
• Real-time event detection with <1 second latency
The Future:
• Perception is the next frontier for AI agents
• The breakthrough isn’t better reasoning—it’s the ability to see, hear, and remember
• Video-native infrastructure makes perception-enabled agents possible today









