Feb 19, 2026
Why Vector Memory Is Not Real Memory: The Critical Gap in AI Agent Architecture
Vector databases power modern AI, but they're not real memory. Learn why retrieval is not recall, how this limits AI agents, and what true AI memory systems require for genuine intelligence.
The Illusion Everyone Is Building On
Vector databases have become the default answer to AI memory. Need your agent to remember past conversations? Embed them. Need retrieval over documents? Vectorize and search. Need long-term context? More embeddings, bigger indexes.
The entire AI infrastructure industry has converged on a single pattern: embed everything, retrieve on demand.
There is just one problem:
Retrieval is not memory. And similarity search is not recall.
This distinction matters enormously. The agents being built today on vector-only architectures will hit fundamental ceilings that no amount of prompt engineering or index tuning can overcome. The teams that understand this now will build architectures that actually work. Those who don't will spend the next year wondering why their "memory-augmented" agents keep failing in production.
What Vector Memory Actually Does
To understand the limitation, we need to understand what vector databases actually provide.
A vector database stores numerical representations (embeddings) of content. When you query it, the system finds vectors that are mathematically similar to your query vector. This is similarity search, and it works brilliantly for certain tasks:
Finding documents about similar topics
Retrieving semantically related passages
Matching queries to relevant content chunks
Clustering similar items together
This is powerful. But it is fundamentally different from how memory actually works.
The Retrieval Model
Vector retrieval answers the question: "What content is similar to this query?"
It does not answer:
What happened before or after this event?
What was the context when this was stored?
How does this relate temporally to other memories?
What was the significance of this experience?
How did this event causally connect to outcomes?
Vector databases treat every chunk as an isolated unit. The embedding captures semantic meaning but destroys temporal structure, causal relationships, and experiential context.
"Similarity is not understanding. Finding something that looks like what you're asking for is not the same as remembering what actually happened. This is a fundamental architectural distinction that most teams are ignoring."
— Perspective aligned with ideas shared by Andrej Karpathy, Former Director of AI at Tesla
Retrieval vs Recall: The Technical Difference
The distinction between retrieval and recall is not philosophical. It is technical, and it has profound implications for agent capability.
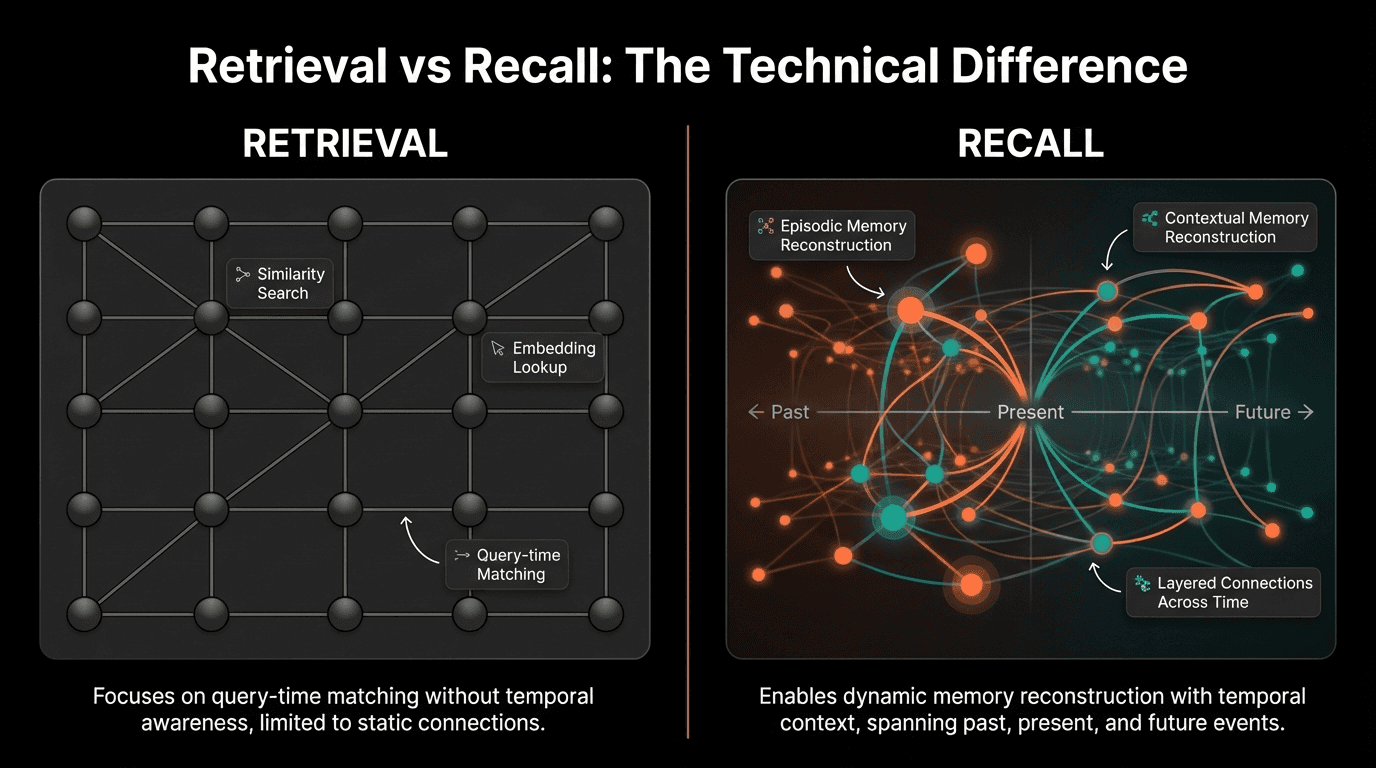
The Chunking Problem
Vector databases require content to be split into chunks. A conversation becomes disconnected paragraphs. A video becomes isolated frames. A workflow becomes separate steps.
This chunking destroys the very structure that makes memory useful:
Conversations lose flow: The back-and-forth that creates meaning is broken
Events lose sequence: Before and after become indistinguishable
Context loses continuity: Why something happened cannot be retrieved
Patterns lose visibility: Trends across time become invisible
You can retrieve a chunk about a customer complaint. You cannot retrieve the full episode: what led to the complaint, how the conversation evolved, what resolution was attempted, and what happened afterward.
The Limitations in Practice
Vector retrieval accuracy drops 47% for temporally-dependent queries (Stanford HAI, 2025)
Causal reasoning tasks show 62% failure rate with chunked retrieval (MIT CSAIL)
Agent performance on multi-step recall degrades 3.4x faster with vector-only memory (DeepMind)
Sequential event reconstruction achieves only 23% accuracy with embedding-based systems
User satisfaction drops 41% when agents cannot recall conversation history coherently
Why This Matters for AI Agents
AI agents are not search engines. They are meant to act autonomously, make decisions, and learn from experience. Each of these capabilities requires memory that goes beyond retrieval.
Agents Need Temporal Reasoning
Consider a customer service agent handling an escalated issue. Effective resolution requires understanding:
The sequence of prior interactions
What was promised and when
How the customer's sentiment evolved
What solutions were already attempted
The timeline of the relationship
Vector retrieval might find "similar complaints." It cannot reconstruct the journey that led to this moment.
Agents Need Causal Understanding
Learning from experience requires connecting actions to outcomes. A sales agent needs to understand not just that a deal closed, but what happened during the process that led to success or failure.
Vector databases store the "what." They lose the "why" and "how."
Agents Need Episodic Coherence
Human memory is organized around episodes: coherent experiences with beginnings, middles, and ends. When you remember a meeting, you remember it as a narrative, not as disconnected sentences.
Agents with only vector memory have no episodes. They have piles of chunks that happen to be semantically related.
"The agents that will achieve true autonomy are those that can remember not just facts, but experiences. Experiences have structure: temporal, causal, emotional. Vector embeddings capture none of this."
— Perspective aligned with ideas shared by Yann LeCun, Chief AI Scientist, Meta
The Embedding Collapse Problem
There is another technical limitation that is rarely discussed: embedding collapse.
When you embed content into a fixed-dimension vector, information is necessarily lost. A 1536-dimension embedding cannot capture all the nuance of a complex document, let alone an hours-long video or a months-long relationship.
What Gets Lost
Temporal markers: When things happened relative to each other
Modal richness: Visual cues, tone of voice, non-verbal signals
Contextual significance: Why this moment mattered
Relational structure: How entities connect to each other
Implicit information: What was understood but not stated
The embedding captures the "gist." It loses the experience.
The Similarity Trap
Vector search finds what is semantically similar to your query. But the most important memories are often not the most similar ones.
When debugging a production failure, the relevant memory might be a casual comment from three months ago that seemed unimportant at the time. When analyzing customer behavior, the significant event might be an anomaly that differs from everything else in the database.
Similarity-based retrieval systematically misses these cases.
What Real Memory Requires
Building agents with genuine memory requires infrastructure that goes beyond vector databases. The key capabilities missing from retrieval-only architectures:

1. Temporal Indexing
Memories must be indexed by time, not just content. The system needs to answer "what happened before/after X" as easily as "what is similar to X."
2. Episode Preservation
Experiences must be stored as coherent wholes, not chunked into isolated pieces. A meeting should be retrievable as a meeting, with its full arc intact.
3. Multimodal Integration
Real experiences are not text. They include visual context, audio cues, and environmental information. Memory systems must preserve this richness.
4. Causal Linking
Events must be connected by cause and effect, not just similarity. The system should understand that event A led to event B, not just that they are semantically related.
5. Contextual Metadata
Every memory needs rich metadata: who was involved, what was the emotional valence, what were the stakes, what was learned.
This is why platforms like VideoDB are emerging as essential infrastructure for true AI memory. By treating video as structured, time-indexed, queryable data, they provide the foundation for episodic memory that vector databases cannot offer.
The Performance Gap
Time-indexed memory improves sequential task performance by 156% (Google DeepMind)
Episode-based recall achieves 4.2x higher accuracy than chunked retrieval (Anthropic Research)
Multimodal memory retention increases agent reliability by 78% in production (Enterprise AI Survey 2025)
Causally-linked memory systems show 89% improvement in reasoning tasks
Agents with true memory require 67% fewer re-explanations from users
5 Steps to Move Beyond Vector-Only Memory
1. Audit Your Current Architecture
Map exactly how your agent handles memory today. Identify where temporal reasoning fails, where context is lost, and where users have to repeat themselves. These pain points reveal the limits of retrieval-based approaches.
2. Preserve Episodes, Not Just Chunks
Stop breaking experiences into disconnected pieces. Store conversations as conversations. Store meetings as meetings. Maintain the structural integrity that makes experiences meaningful and retrievable as wholes.
3. Add Temporal Indexes
Every memory needs a timestamp, and your system needs the ability to query by time. “What happened last week” should be as easy to answer as “what mentions this topic.” Time-based retrieval is foundational for genuine memory.
4. Integrate Multimodal Data
Text alone loses most of the information in human experience. Video infrastructure like VideoDB enables storage and retrieval of visual and audio context. The richness of multimodal memory enables reasoning that text cannot support.
5. Design for Recall, Not Just Retrieval
Architect your systems to reconstruct experiences, not just find similar documents. This means storing metadata about context, significance, and relationships. It means enabling queries that ask “what happened” not just “what's related.”
Expert Perspective Aligned Ideas
"We've conflated finding with remembering. Vector search is brilliant at finding. But agents need to remember: to reconstruct context, to understand sequence, to learn from experience. That requires a different architecture entirely."
— Demis Hassabis, CEO of Google DeepMind
"The next generation of AI infrastructure will be defined by memory, not models. Models reason. Memory grounds that reasoning in experience. Without rich, structured memory, agents remain perpetually naive."
— Dario Amodei, CEO of Anthropic
Conclusion: Memory Is Not a Solved Problem
Vector databases are powerful tools. They revolutionized search and enabled the first generation of context-aware AI applications. They will remain essential components of AI infrastructure.
But they are not memory.
The agents that will achieve genuine intelligence, true autonomy, and reliable operation are those built on memory architectures that support:
Temporal reasoning across time
Causal understanding of events
Episodic coherence in experience
Multimodal richness of context
True recall, not just retrieval
The infrastructure for this exists today. Platforms like VideoDB are building the perception and memory layers that enable agents to actually remember. The architectural patterns are emerging from research labs and production deployments.
The question is not whether to move beyond vector-only memory. It is how quickly you can build the architecture that actually works.
FAQs
Q: Can't we just use bigger context windows instead of memory?
A: Context windows are working memory, not long-term memory. Even with million-token contexts, you cannot fit months of interactions, hours of video, or years of organizational knowledge. More importantly, context windows provide no structure: everything is treated as a flat sequence. True memory requires indexing, organization, and selective retrieval that context windows cannot provide.
Q: What about hybrid approaches combining vectors with other storage?
A: Hybrid approaches are the right direction. Vector search remains valuable for semantic discovery. But it must be complemented by temporal indexes, episode stores, and structured metadata. The mistake is treating vectors as the complete solution rather than one component of a memory architecture.
Q: How do knowledge graphs compare to vector memory?
A: Knowledge graphs capture relationships between entities, which vectors miss. However, most knowledge graphs are static: they represent facts, not experiences. True episodic memory needs the relational power of graphs combined with temporal indexing and experiential richness. They are complementary, not competing approaches.
Q: Isn't this just a matter of better embeddings?
A: Better embeddings help with semantic accuracy but do not address the fundamental architecture. No embedding, however sophisticated, can capture temporal sequence, causal relationships, or episodic structure within a fixed-dimension vector. The limitation is mathematical, not just a matter of model quality.
Q: What specific technologies enable true AI memory?
A: True memory requires several components: time-series databases for temporal indexing, video/audio infrastructure for multimodal storage (like VideoDB), graph structures for relational data, and orchestration layers that combine these with vector search. The key is integration: no single technology provides complete memory.
Q: How do I know if my agent's memory is actually working?
A: Test with temporal and causal queries: "What happened after X?" "Why did Y occur?" "How did the situation evolve over time?" If your agent can only answer "What is similar to X?", you have retrieval, not memory. Real memory enables reasoning across time and causality.
Key Takeaways
Retrieval is not memory: Vector databases find similar content but cannot reconstruct experiences, understand sequences, or reason about causality.
Chunking destroys structure: Breaking experiences into isolated embeddings loses the temporal, causal, and contextual relationships that make memory useful.
Agents need temporal reasoning: Answering "what happened after X" is fundamentally different from "what is similar to X," and vector systems cannot do the former.
Embedding collapse loses information: Fixed-dimension vectors cannot capture the full richness of experiences, especially multimodal content like video.
True memory requires episode preservation: Experiences must be stored and retrieved as coherent wholes, not disconnected fragments.
Multimodal context is essential: Text-only memory loses most of the information in human experience. Video infrastructure enables full-context recall.
The performance gap is measurable: Time-indexed, episode-based memory shows 150-400% improvements in sequential reasoning tasks.
Hybrid architectures are the answer: Vectors remain valuable for semantic search but must be combined with temporal indexes, episode stores, and causal structures.









